



Click the topic to read previous chapters:
Chapter I: Overview of AI Technology
Chapter III (part 1) Patent Protection of AI in China and Other Major Jurisdictions
Chapter III (part 2) Patent Protection of AI in China and Other Major Jurisdictions

Chapter IV Copyright Protection of AI
4.1 Subject Matter Protected by AI Copyright
4.1.1 Overview
The subject matter protected by AI-related copyright, namely works, may include the following types:
Graphic works and model works such as product design drawings
AI-related product design drawings and model works can be used as the bottom protection for graphic works and model works such as product design drawings. However, the copyright protection of product design drawings can only protect the reproduction from plane to plane, that is, prevent others from reproducing the drawings themselves, instead of preventing others from designing the same products according to the drawings.
Computer software
While applying for patent protection for the “creative ideas” of AI software, it is also possible to apply for copyright registration for the “form of expression” of the software. There are many kinds and large quantities of software with different functions involving AI technology, almost covering the various technical layers of AI (basic support layer, general technology layer and application layer).
Fine art works
AI may also involve a variety of fine art works, including logo graphics of software, AI virtual robot image design, and others.
An AI virtual image costs a designer’s great efforts, so a unique design is more likely to be counterfeited, making the protection of AI virtual image tricky. If image protection is involved, the relevant provisions of the Copyright Law are first considered. The AI virtual image can be classified as a fine art work. As a designer (or commissioned designer) of a fine art work, an AI company enjoys copyright to its image, and unauthorized use of others’ AI image constitutes an infringement upon copyright.
If the human-computer interaction interface of AI has strong originality and artistic design, it can also be protected by copyright as a fine art work.
The following mainly introduces the computer software protection of AI.
4.1.2 Copyright protection term of AI software
According to Article 14 of the Regulation on Computers Software Protection of the People’s Republic of China, software copyrights shall arise from the date of completion of software development.
The software copyright of a natural person shall be protected for the whole life of the natural person and 50 years after his/her death, and expire on December 31 of the 50th year after the death of the natural person; Where the software is co-developed, its copyright will expire on December 31 of the 50th year after the death of the natural person who dies last.
The software copyright of a legal person or other organizations shall be protected for 50 years, and expire on December 31 of the 50th year after the software is first published, but the software will no longer be protected by this Regulation if it has not been published within 50 years as of the completion of the development.
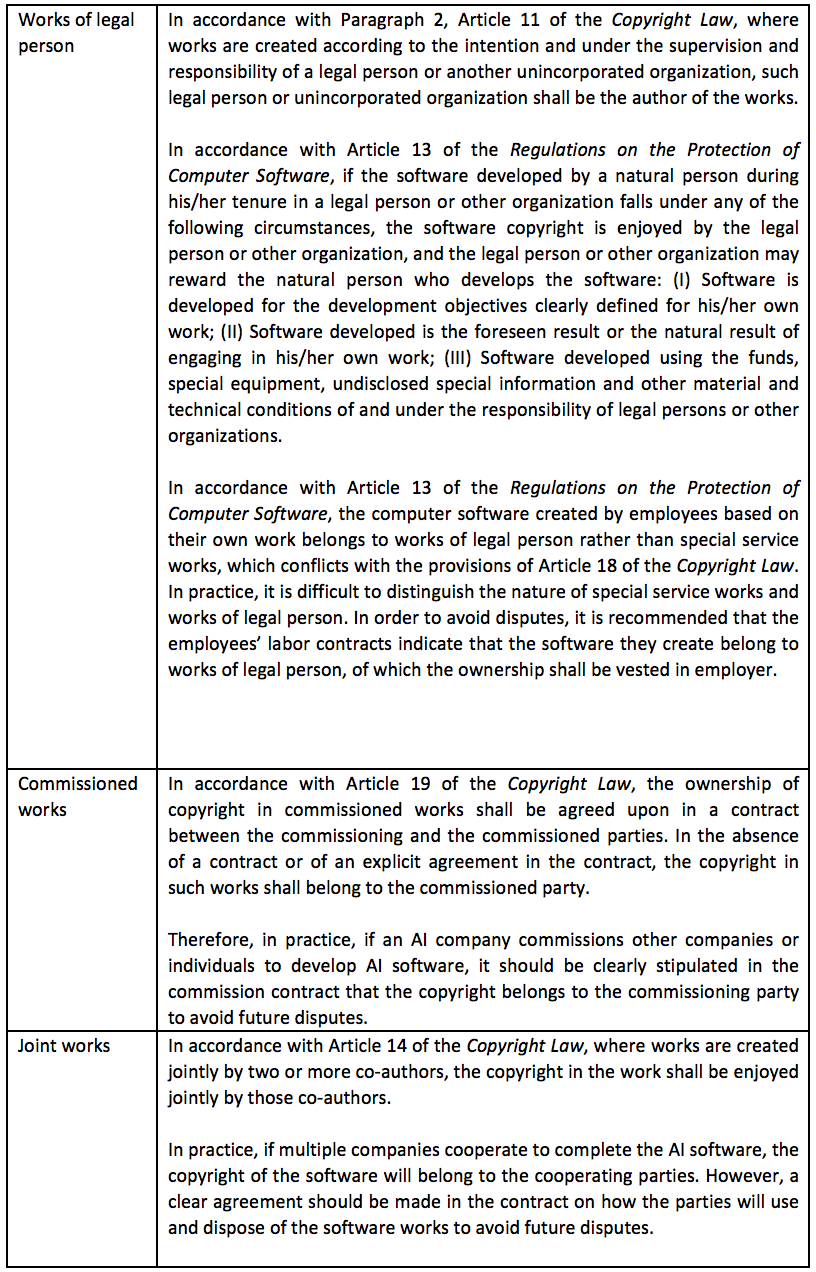
4.1.3 Copyright ownership of AI software
In accordance with the Copyright Law of the People’s Republic of China, the copyright ownership of AI software may be divided into the following categories.

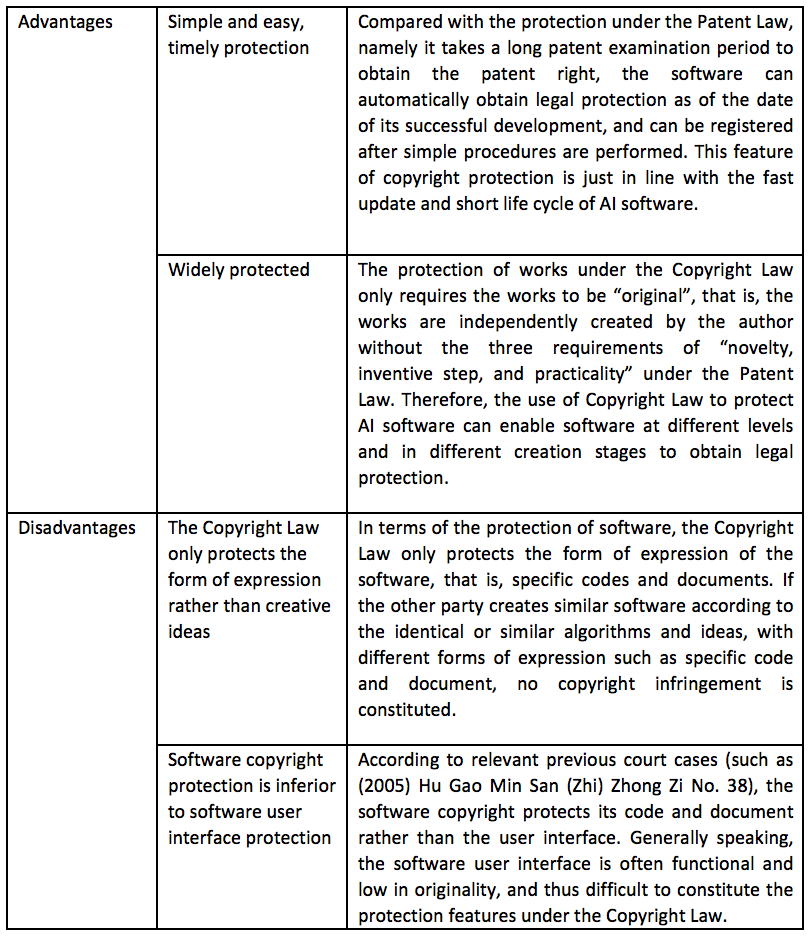
4.1.4 Protection Features of AI Software
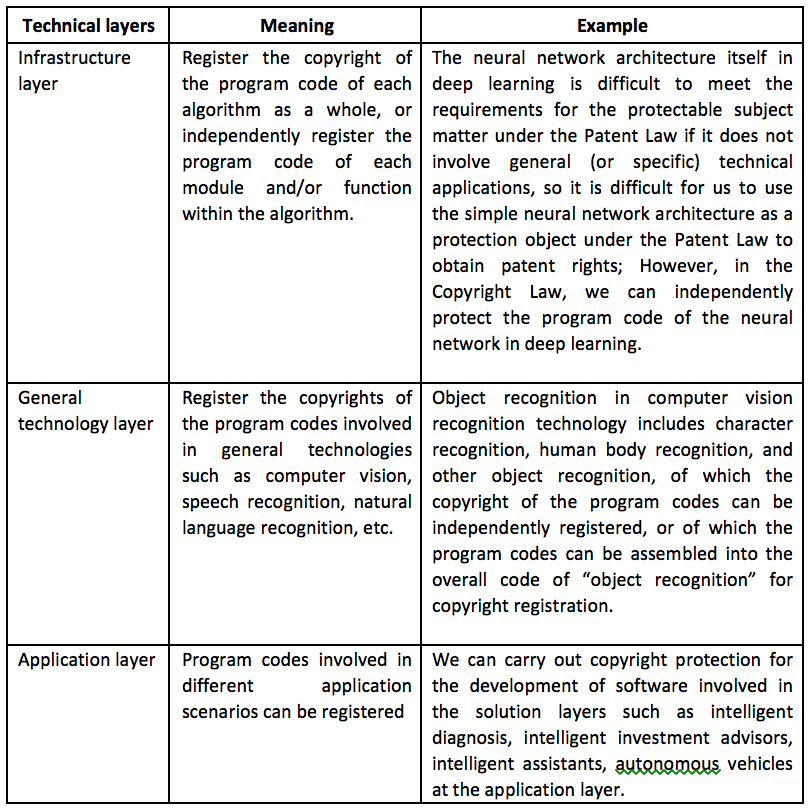
4.1.5 Protection object of AI software
Computer software refers to “computer programs and related documents”.
Computer programs comprise “coded instruction sequences”, or “symbolized instruction sequences or symbolized sentence sequences that can be automatically converted into coded instruction sequences”. The source code and target code of the same computer program are the same works.
Documents refer to “text data and diagrams used to describe the content, composition, design, functional specifications, development status, test results, and usage methods of the program, etc.”, such as program design specifications, flowcharts, user manuals, etc. (Article 2, Paragraphs 1 and 2 of Article 3 of the Regulations on the Protection of Computer Software)
Generally speaking, the functional modules, functions, source programs, target programs, program specifications, flowcharts, user manuals, etc. of the software can all serve as the protection objects under the Copyright Law.
Specifically, in terms of the various technical layers of AI, the documents in the software copyright protection are similar, and the protection objects of its computer programs are briefly analyzed as follows:
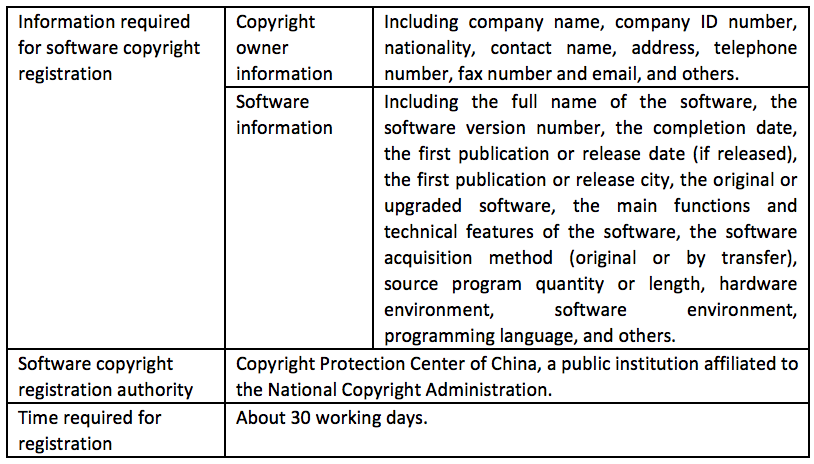
4.1.6 Copyright registration of AI software
According to the Copyright Law of the People’s Republic of China, copyright is automatically enjoyed when the creation of works is completed, without taking copyright registration as a prerequisite. However, copyright registration is conducive to proving ownership, avoiding future ownership disputes, and facilitating future rights protection by litigation. Therefore, it is recommended to register the copyright of AI software.
4.2 Copyright protection of AI product
The AI at the basic support layer and general technology layer may not involve the copyright protection of product. While the AI at the application layer, such as automatic writing robot, automatic composing robot, and automatic drawing robot involves the issue of whether the products (written works, music, fine art works, etc.) created by such AI are protected by copyright.
4.2.1 Traditional point of view: the AI product does not belong to works protected by Copyright Law
According to the traditional theory and practice under the Copyright Law, the content created by AI is not regarded as works in the sense of Copyright Law and cannot be protected by copyright. The reasons are:
1. It is not created by a natural person. According to the Copyright Law, works must be created by natural persons. Although legal persons or unincorporated organizations can also be identified as authors, such identification is a legal fiction, and works of legal person are fundamentally created by natural persons.
2. It is not original. It is believed that works created by AI are only the processing and arrangement of data, which do not meet the definition of creation, and are not considered to be original.
When the monkey’s “self-portrait” caused a copyright ownership dispute in the United States in 2015, the U.S. Copyright Office clearly indicated that only human works are protected by U.S. Copyright Law, and the Office will not accept copyright registration of works created by nature, animals, or plants. Therefore, the monkey’s self-portrait is not copyrighted. The San Francisco Federal Court also finally ruled in support of the U.S. Copyright Office’s decision: animals cannot own the copyright to their photos.
4.2.2 Practice development: limited recognition of obtaining copyright protection
Despite the above-mentioned legal obstacles, due to the existence of a large number of works created by AI in practice and the fact that they have important economic value and legal protection significance, the academic and practical circles are increasingly inclined to protect the copyright of works created by AI.
Reasons for advocating copyright protection of AI products:
1. AI is just a tool, not a creator. The actual creator of AI products is essentially human rather than AI.
2. AI products have the originality required by the Copyright Law. AI products are not simple and mechanical data processing, but also embody human wisdom and creation. With the development of AI technology, AI products have reached the level of human creations. Without prior explanation, it is difficult for ordinary people to distinguish from their appearance which are AI products and which are works created by natural persons.
Typical Cases:
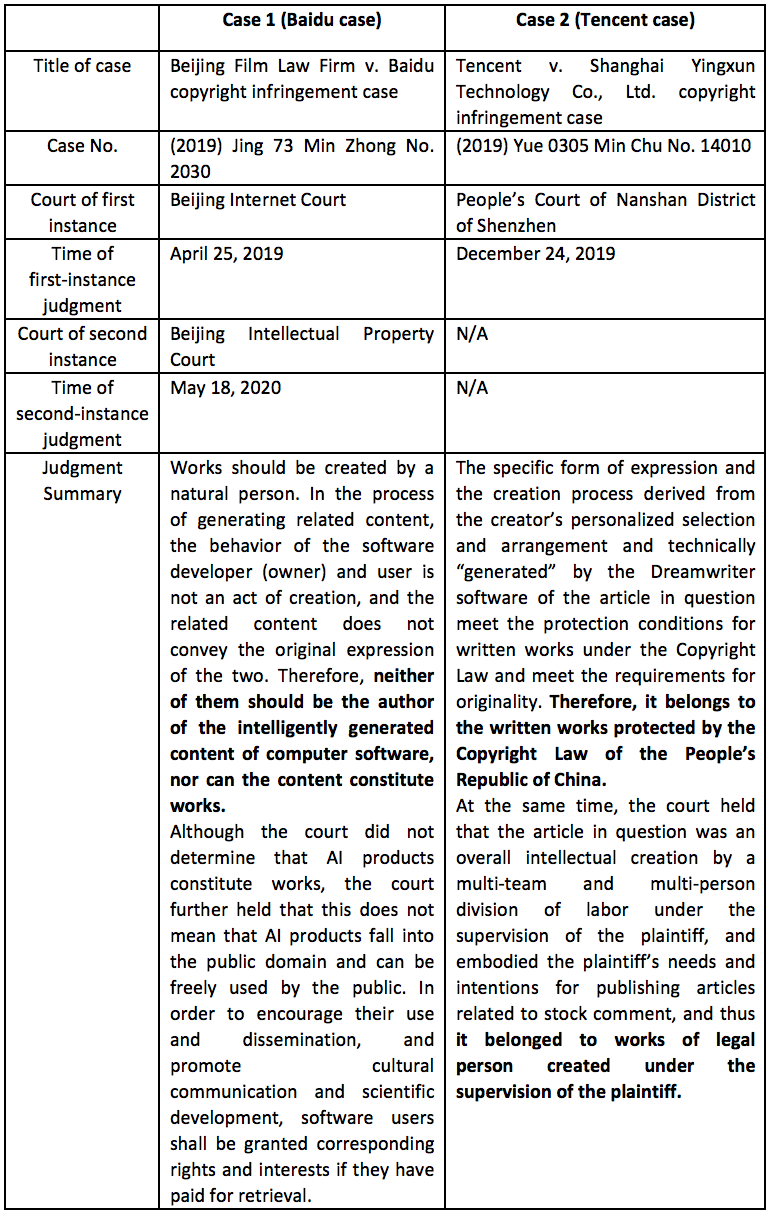
Difference in the judgments on the two cases:
●In Case 1 (Baidu case), the court held a conservative position and held that the product of AI software was not works under the Copyright Law, but determined that the software users should be granted corresponding rights and interests;
●In Case 2 (Tencent case), the court further held that AI software was only a tool, and that the product created by using AI software was still the result created by human beings, and thus determined that the product of AI software should be protected in accordance with the Copyright Law.
AI can be divided into three layers: weak AI, strong AI, and super AI. Weak AI is only equivalent to an enhanced version of tools. Works created using it can be certainly regarded as works created by natural persons and should be protected by Copyright Law. Super AI has not yet been fully realized. From the current practice, strong AI is still inclined to be protected under the Copyright Law (such as the Tencent case), or granted a certain degree of protection (such as in the Baidu case) on the premise that it is not recognized to constitutes works.
However, in the Baidu case and the Tencent case, judgments are only made on individual circumstances, and it is hard to say that they have given clear and universal guidance on the copyright of AI products. Especially for some complicated situations, more judgments may be required in the future. We will continue to pay attention to relevant judicial and legislative developments to provide more in-depth analysis and guidance for AI companies.
4.2.3 Copyright ownership of AI product
Based on the judicial decision on the Tencent case, Chinese courts are currently inclined to protect AI products, provided that they determine that the products are still the results created by human beings, and the author is human rather than AI itself. After solving the problem of whether the AI product can be protected by the Copyright Law, it is necessary to analyze to which subject the copyright of the AI product should belong.
● AI Developer
There is a view that the AI product should fundamentally belong to the developers of AI software. In the process of AI generation, software developers have contributed the most and gained the most technical achievements; while users of AI software get the products only by inputting data or instructions, with the creation process all made by the AI software. Therefore, the copyright of AI product should be vested in AI developers so as to better protect the interests of developers, and encourage and stimulate the development of AI industry.
● AI User
There is another view that the AI software is essentially just a tool. Works created by humans using AI software is just like those created using other created tools, of which the copyright should belong to the users of AI software. For example, humans use cameras to take photos. Although camera manufacturers have made great contributions to the design and development of cameras, and the process of taking photos is simply a click of the shutter, the copyright of the photos should still belong to the persons who took the photos. In addition, another reason is that developers have already obtained sufficient commercial profits by selling AI software, and its protection should not be extended to its products. Otherwise, users of AI software will lose the control over the works created using such software, and it is also not conducive to the growth of the AI software industry.
● Court’s Point of View – AI User
In the Baidu case, although the court did not held that AI products are works in the sense of Copyright Law, it further pointed out that AI users should be granted relevant rights and interests: “Software developers (owners) can obtain benefits by charging software royalties, etc., and their development investment has been rewarded accordingly; moreover, the analysis report is generated by software users according to different usage requirements and retrieval settings, for which the software developers (owners) lack dissemination motivation. Therefore, the relevant rights and interests in and to the analysis report will not be applied actively by the software developers (owners) if they are granted to them, which is not conducive to the development of cultural communication and scientific undertakings. Software users make an investment through paid use, set keywords based on their own needs and generate analysis reports, having the motivation and expectations for further use and dissemination of the analysis reports. Therefore, software users should be granted the relevant rights and interests in and to the analysis reports to encourage their use and dissemination. Otherwise, the software users will gradually decrease, and be unwilling to further disseminate the analysis reports, which is ultimately not conducive to cultural dissemination and value development.”
In the Tencent case, the court held that: the article in question was an overall intellectual creation by a multi-team and multi-person division of labor under the supervision of the plaintiff, and embodied the plaintiff’s needs and intentions for publishing articles related to stock comment. The article in question was published on the Securities Channel of Tencent Net operated by the plaintiff, at the end of which it is indicated that “this article is automatically written by Tencent Robot Dreamwriter”, and in which the authorship of “Tencent” should be understood as the plaintiff in combination with its publishing platform, indicating that the plaintiff bears responsibility for the article in question. Therefore, in the absence of evidence to the contrary, the court determined that the article in question was works of legal person created under the supervision of the plaintiff.
Based on the judgments on the two cases, it was determined in the Tencent case that the plaintiff Tencent, user of the AI software Dreamwriter, was the author of the article in question and only used AI software as a tool for creation. The court held that the article in question embodied the special selection and arrangement of the chief creators of the plaintiff, expressed the unique personality of the software user, and reflected the will of the software user. In the Baidu case, although the court didn’t recognize that AI products should be protected by copyright, it emphasized the grant and protection of certain rights and interests, which should belong to users of AI software, rather than developers.
Conclusion:
In accordance with the provision of the Copyright Law of the People’s Republic of China that “works must be created by a natural person”, it may be a more reasonable inference to determine that the user of AI software is the author of the AI product, otherwise it is difficult to reasonably explain where the process of “creation” is embodied, and how it is made by “human beings”.
● Obligation to indicate AI software product
Although affirming that AI users enjoy rights and interests in and to their products, in the Baidu case, the judge emphasized that users should indicate that AI products were generated by some AI software, for the purpose of explaining to the public the creation of their works and satisfy the public’s right to know; and protecting the interests of AI developers, making the relevant public aware of the AI software, expanding the popularity and influence of AI software, thereby achieving a balance between the interests of AI users and developers.
● Agreement on product copyright ownership
In the Tencent case, Tencent Technology (Beijing) Co., Ltd., the developer of the AI software Dreamwriter, and the plaintiff Shenzhen Tencent Computer System Co., Ltd., the software user, agreed that the copyright of the software product belongs to the plaintiff, on which the court did not make any comment.
Considering that the current legislation does not clearly stipulate the copyright of AI products, it is recommended that AI companies specify the copyright ownership of AI products in the software licensing agreement to avoid possible future disputes.
4.3 Copyright Issues in Machine Learning
Machine learning is the key technology of AI, which has not only brought many social issues, but also challenged the existing legal system with the rapid development and widespread application of AI technology. Machine learning uses a large amount of “data” as training data, which can be divided into two categories: data, information or works not protected by Copyright Law, and works protected by Copyright Law. The former category is protected by data regulations such as the Personal Information Protection Law, while the latter category may involve various copyright infringement risks.
Machine learning is divided into three stages, namely input stage, learning stage and output stage. At the input stage, the collected data is input into the preliminary model so that the preliminary model can analyze the data through algorithms; At the learning phase, the training data is analyzed, model is optimized, and task is completed by relying on the powerful processing and computing power of the computer; The output stage is the last stage of machine learning, at which the task is processed through the model to obtain the corresponding answer. At each stage, the potential copyright issues are different from time to time.
4.3.1 Input Stage
The sources of input training data in machine learning can be roughly divided into the followings:
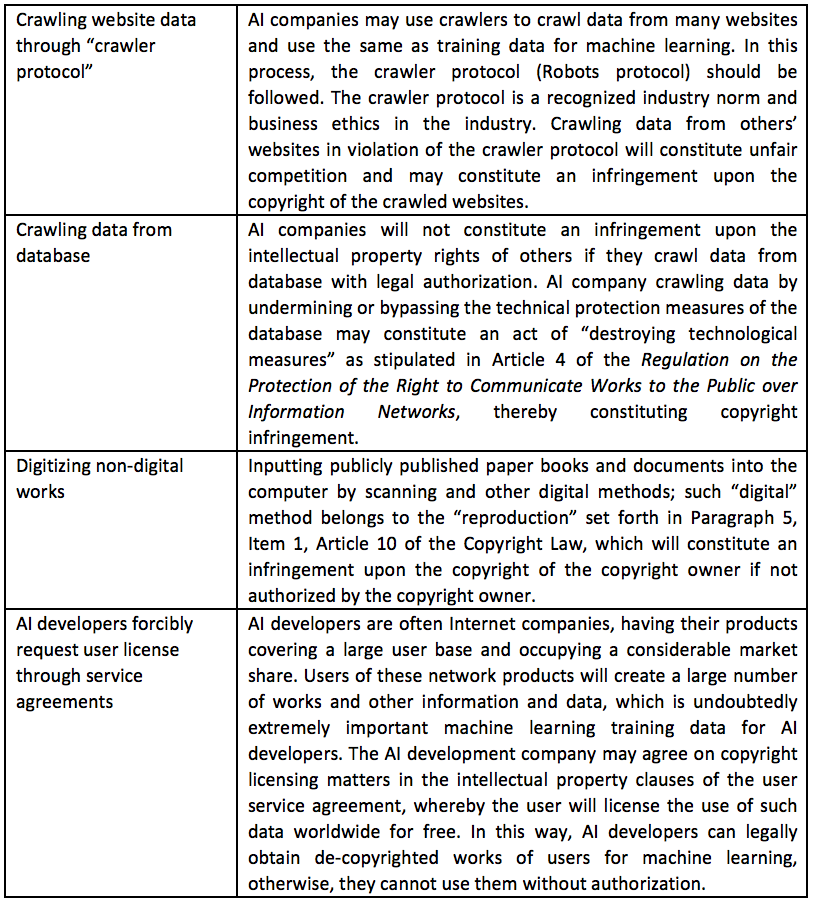
Conclusion:
Crawling and reproducing others’ works for input without authorization involves a higher risk of copyright infringement. However, the input stage is often an act that occurs within the company, and it is generally difficult to be discovered, so the possibility of being sued for copyright infringement is low in practice.
4.3.2 Leaning Stage
The process at the learning stage involves reproduction, translation, adaption, and compilation of training data. Do these acts of use constitute copyright infringement of works? There are several points of view as follows.
● Constitute Copyright Infringement
There is a view that the use of copyrighted works as training data by machine learning at the learning stage is the use of works by reproduction, translation, adaptation, and compilation. Therefore, the use of these works by machine learning must be authorized by the copyright owner, otherwise it will constitute copyright infringement.
However, this view does not take into account the current status and particularity of machine learning. Since machine learning requires improvement using the massive amounts of data, if strict protection requires AI companies to obtain authorization from the author of each piece of works in advance, it is almost impossible to complete the task, will greatly damage the normal development of the AI industry, and will not be conducive to the balance of interests between the AI industry and copyright owners.
● Belong to Fair Use
Existing foreign legislation and judicial practice seem to be inclined to apply the fair use system to machine learning in order to exempt its infringement liability. For example, the exceptions to text data mining (Articles 3, 4 and 7) in the EU’s 2019 Directive on Copyright in the Digital Singles Market (Articles 3, 4, 7), and the US court found that text data mining constitutes fair use and rejected the Authors Guild’s a series of infringement lawsuits against Google Books project.
Correspondingly, most scholars at home and abroad also advocate adopting a fair use system to solve the copyright issues in machine learning works.
Article 24 of the Copyright Law of the People’s Republic of China stipulates the fair use system. To satisfy fair use, four requirements must be met: (1) Thirteen specific items; (2) Specify the name or title of the author and the title of works; (3) Not affect the normal use of works; (4) Not unreasonably damage the legal rights and interests of the copyright owner.
Others’ works used in machine learning are only input as training data into the computer system for practicing by machine, of which the process occurs at the machine level, so under normal circumstances it will not affect the normal use of works, nor unreasonably damage the legal rights and interests of copyright owners.
However, the difficulty in applying the fair use clause is that the thirteen specific items set forth in this article must be conformed to, which, however, do not explicitly include machine learning. Among the 13 items, the most related item may be “(6) for the purpose of school classroom teaching or scientific research, the published works are translated, adapted, compiled, broadcast or reproduced in small quantities for use by teaching or scientific research personnel, instead of being published or distributed”, which, however, emphasizes “scientific research, and for use by teaching or scientific research personnel”; although the process of machine learning is related to scientific and technological research, it is a commercial activity after all. Therefore, it is difficult to apply this item since it requires non-commercial and simple research field. In addition, although the last one “(13) other circumstances provided for by laws and administrative regulations” in the 13 items seems to be an open clause, it also cannot be applied since the “laws and administrative regulations” are defined, but machine learning is not determined as fair use by laws or administrative regulations at present.
Therefore, under the current Copyright Law of the People’s Republic of China, it is difficult to identify the learning stage of machine learning as fair use.
● Belong to Use in the Sense of Non-copyright
There is another view that the “use” of copyrighted works in the learning process is different from the “use” in the sense of the traditional Copyright Law. The subject of the “use” set forth in the Copyright Law is human, namely “human reading”; while in machine learning, the subject of the use is “machine”, namely “machine reading”. In this sense, the works used in the machine learning process are just converted into a language understood by the machine in a machine way for learning. The text processing process is only a mechanical processing process rather than the use of works. Therefore, the learning process of machine learning should be regarded as use not in the sense of Copyright Law, and naturally does not constitute copyright infringement.
Conclusion:
Regarding the learning stage of machine learning, there are currently no clear regulations in legislation, and there are no relevant case references in judicial practice. The main point of view in academic circles is that it constitutes fair use or use not in the sense of Copyright Law, thereby exempting it from the risk of copyright infringement. The identification of its nature may be further defined in legislation or judicial practice in the future.
4.3.3 Output Stage
At the learning stage of machine learning, the risk of infringement may be exempted using fair use or use not in the sense of Copyright Law, but there is still a greater risk of copyright infringement at the output stage.
According to whether the output result of machine learning is original, machine learning can be divided into expressive machine learning and non-expressive machine learning. The output result of non-expressive machine learning is not original, while that of expressive machine learning has a certain originality.
● Non-expressive Machine Learning:
No expressive content is output, and the reproduction of works in the process of machine learning does not result in the public dissemination of expressive content of subsequent works. Therefore, works created by this type of machine learning will not be identical or substantially similar to the works it is learning, and will be exempted from liability for copyright infringement.
● Expressive Machine Learning:
Expressive machine learning can be divided into ordinary expressive and special expressive types. Ordinary expressive type does not take the style of a specific author as a model object; while special expressive type aims to imitate a certain style of an author.
(1) In terms of ordinary expressive type, its training data is sourced from a large number of authors, and its output result integrate the styles and expressions of multiple authors, making it difficult to determine the similarity with works of a specific author. Generally speaking, it will not constitute copyright infringement. However, if some of the expressions in the output result are obviously similar to works of some authors even though it comes from multiple authors, the similar part will constitute copyright infringement.
(2) In terms of special expressive type, it aims to imitate and reproduce the expression of a specific author’s works, with the technical goal of approximating such author’s creation style indefinitely, so the information extracted by this kind of AI from works is essentially a consistent personalized expression of an author, and the personalized expression of works created by this kind of AI may also have the market effect of replacing learning authors. Therefore, in this case, the possibility of copyright infringement is high. For this type of machine learning, AI companies should obtain the author’s license in advance.
Typical Case:
In the copyright infringement case of the hit drama Princess Weiyoung, the author Qin Jian was accused of plagiarizing 219 pieces of works using “writing software”. After more than two years of defending rights, 12 authors won all the plagiarism cases against Princess Weiyoung. In May 2019, the People’s Court of Chaoyang District, Beijing made a judgment that: Compared with the 16 pieces of works previously published by 12 well-known authors such as Wen Rui’an, the novel Princess Weiyoung also uses unique metaphors or descriptions in terms of sentences, or uses the same or similar details to describe people or things, or uses similar combinations of a large number of commonly used languages; in terms of the plot, the novel Princess Weiyoung adopts the original background settings, appearance arrangements, conflicts and specific plot designs of the said 16 pieces of copyrighted works, with identical or substantially similar contents in 763 sentences and 21 plots, involving a total of 114 thousand words. The writing software used by the author Qin Jian learns the works of others through machines, and outputs the results at the users’ demands, but uses a large number of language expressions or similar combinations of the learning content, constituting a substantial similarity to the multiple works in question. Therefore, the novel Princess Weiyoung constitutes copyright infringement.
The determination of the infringing subject is also involved in the determination of infringement of output of machine learning. As mentioned in the previous section, current judicial practice tends to identify software users as the authors of AI products, and software users should bear the liability for infringement. However, software users may require the developers of AI software to bear the liability for compensation on the grounds of the “defect guarantee obligation” set forth in the Product Quality Law.