



Click the topic to read previous chapters:
Chapter I: Overview of AI Technology
Chapter III (part 1) Patent Protection of AI in China and Other Major Jurisdictions

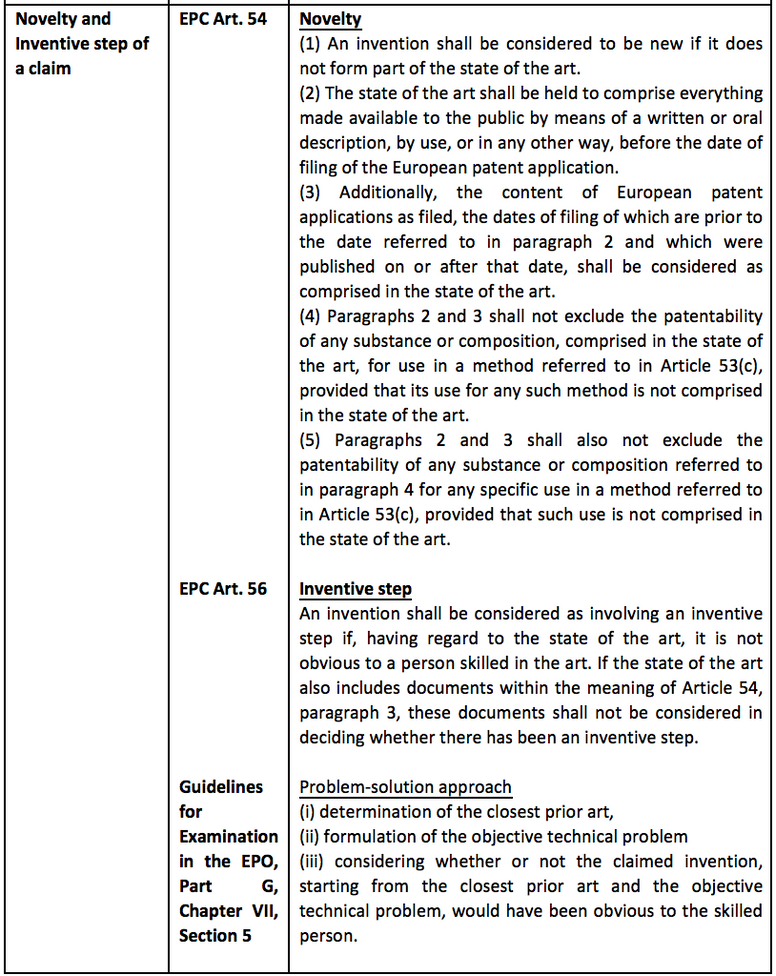
3.3 AI-related Patent Practice in Europe
This section will introduce the patent practice related to artificial intelligence (AI) under the European Patent Law.
3.3.1 AI-related Revision to the EPO Guidelines for Examination
With the fast development of AI technology, the number of patent applications in various countries has increased rapidly. In this context, major intellectual property powers have adjusted their patent examination standards in succession and formulated provisions on patentability of AI technology. In order to meet this demand, the European Patent Office (EPO) has revised the Guidelines for Examination in the EPO respectively in 2018, 2019 and 2021, as shown in the following table.

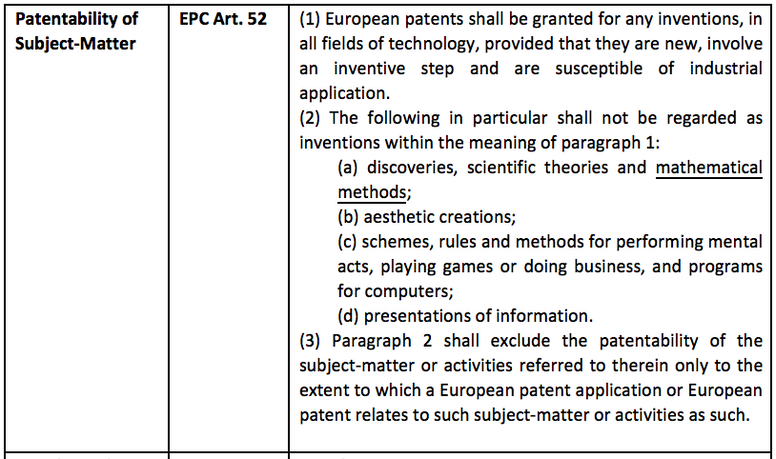
3.3.2 Main provisions of the EPC regarding the grant of patent rights
The main provisions regarding the grant of patent rights (including the grant of patent rights related to AI technology) in the European Patent Convention (EPC) are shown in the following table.
3.3.3 Regarding Patentability
3.3.3.1 “Invention” must have a technical character in accordance with EPC Art. 52 (1)
It is regulated in Section 1, Chapter II, Part G of the Guidelines for Examination in the EPO that, “an “invention” within the meaning of Art. 52 (1) must be of both a concrete and a technical character.” Furthermore, it is regulated in Section 2, Chapter I, Part G of the Guidelines for Examination in the EPO, that, the invention must be of “technical character” to the extent that it must relate to a technical field, must be concerned with a technical problem and must have technical features in terms of which the matter for which protection is sought can be defined in the claim.
3.3.3.2 Principle of determining whether the subject-matter of a claim has a technical character
Section 3, Chapter II, Part G of the Guidelines for Examination in the EPO has specified several general aspects that need to be paid attention to when considering whether the subject-matter of an application is an invention within the meaning of EPC Art. 52(1). Firstly, any exclusion from patentability under EPC Art. 52(2) applies only to the extent to which the application relates to the excluded subject-matter as such [EPC Art. 52(3)]. Secondly, the subject-matter of the claim is to be considered as a whole, in order to decide whether the claimed subject-matter has a technical character. If it does not, there is no invention within the meaning of EPC Art. 52(1). It must also be borne in mind that the basic test of whether there is an invention within the meaning of EPC Art. 52(1) is separate and distinct from the questions whether the subject-matter is susceptible of industrial application, is new and involves an inventive step. Technical character is assessed without regard to the prior art.
3.3.3.3 Specific explanation on determining whether the subject-matter of an AI-related claim has a technical character
According to the provisions of the above-mentioned EPC Art. 52(2) and (3), a purely abstract mathematical method is not patentable. However, Section 3.3 “Mathematical methods” under Chapter II, Part G provides that based on the principle of determining whether the claimed subject-matter has a technical character as a whole, if a claim is directed either to a method involving the use of technical means or to a device, its subject-matter is not excluded from patentability under EPC Art. 52(2) and (3) and is thus an invention within the meaning of EPC Art. 52(1). According to Section 3.3.1, Chapter II, Part G, artificial intelligence and machine learning are based on computational models and algorithms, which are per se of an abstract mathematical nature. Hence, the guidance provided in Section 3.3 “Mathematical methods”, Chapter II, Part G of the Guidelines generally applies also to such computational models and algorithms.
A mathematical method may contribute to the technical character of an invention, i.e. contribute to producing a technical effect that serves a technical purpose, by its application to a field of technology and/or by being adapted to a specific technical implementation.
Mathematical Methods:
Section 3.3, Chapter II, Part G provides examples of mathematical methods being considered to be applied to a field of technology and/or be adapted to a specific technical implementation.
· Examples of technical purposes which may be served by a mathematical method are :
- controlling a specific technical system or process, e.g. an X-ray apparatus or a steel cooling process;
- determining from measurements a required number of passes of a compaction machine to achieve a desired material density;
- digital audio, image or video enhancement or analysis, e.g. de-noising, detecting persons in a digital image, estimating the quality of a transmitted digital audio signal;
- separation of sources in speech signals; speech recognition, e.g. mapping a speech input to a text output;
- encoding data for reliable and/or efficient transmission or storage (and corresponding decoding), e.g. error-correction coding of data for transmission over a noisy channel, compression of audio, image, video or sensor data;
- encrypting/decrypting or signing electronic communications; generating keys in an RSA cryptographic system;
- optimising load distribution in a computer network;
- determining the energy expenditure of a subject by processing data obtained from physiological sensors; deriving the body temperature of a subject from data obtained from an ear temperature detector;
- providing a genotype estimate based on an analysis of DNA samples, as well as providing a confidence interval for this estimate so as to quantify its reliability;
- providing a medical diagnosis by an automated system processing physiological measurements;
- simulating the behaviour of an adequately defined class of technical items, or specific technical processes, under technically relevant conditions (see G‑II, 3.3.2).
· Examples of being adapted to a specific technical implementation is:
- adaptation of a polynomial reduction algorithm to exploit word-size shifts matched to the word size of the computer hardware.
Artificial Intelligence and Machine Learning:
Section 3.3.1, Chapter II, Part G provides examples of technical application of artificial intelligence and machine learning.
· Examples of technical application of artificial intelligence and machine learning are:
- use of a neural network in a heart-monitoring apparatus for the purpose of identifying irregular heartbeats makes a technical contribution;
- classification of digital images, videos, audio or speech signals based on low-level features (e.g. edges or pixel attributes for images) are further typical technical applications of classification algorithms.
(2) Case Examples
Example 1 (EP1770612B1):
A computer-implemented method for parallel training a support vector machine using a plurality of processing nodes and a centralized processing node connected to a network of processing nodes based on a set of training data, each of the processing nodes stores a subset of a kernel matrix only, comprising the steps of:
a) at each of the plurality of processing nodes, selecting a local working set of training data based on said set of training data;
b) at each of the plurality of processing nodes, transmitting selected data related to said local working set of training data to said centralized processing node, said selected data comprising gradients of said local working set of training data;
c) at each of the plurality of processing nodes, receiving an identification of a global working set of training data selected, at said centralized processing node, based on the data transmitted from the plurality of processing nodes, said identification being sent by said centralized processing node;
d) at each of the plurality of processing nodes, optimizing said global working set of training data by executing a quadratic function;
e) at each of the plurality of processing nodes, updating a subset of gradients of said global working set of training data, the step of updating comprising computing the subset of the kernel matrix, wherein said subset of gradients corresponds to said subset of the kernel matrix; and
f) repeating said steps a) through e) until a convergence condition is met, the convergence condition being the Karush-Kuhn-Tucker condition.
Analysis:
This application involves an algorithm for support vector machine filed in 2006, which is an improvement to the algorithm and does not provide “technical features” in the traditional meaning, and the application has been granted in Europe in 2016. The following is a brief description of the examination process:
During the examination of the original application documents (EP1770612), the EESR alleged that, “No technical effect of the features of the method can be determined by the examiner. In particular, the output of the method is not used in any technical application, no technical considerations are required to carry out the claimed method, and no details of implementation are claimed either. Therefore, claim 1 does not have a technical character and is merely a mathematical method.” Specifically, original claim 1 is as follows:
A method for training a support vector machine based on a set of training data at one of a plurality of processing nodes, comprising the steps of:
a) selecting a local working set of training data based on local data;
b) transmitting selected data related to said local working set;
c) receiving an identification of a global working set of training data;
d) optimizing said global working set of training data;
e) updating a portion of gradients of said global working set of training data; and
f) repeating said steps a) through e) until a convergence condition is met.
The applicant has made the following amendments to claim 1 and requested for substantive examination, and argued in the reply to the EESR filed that, “The support vector machine running on a network of processing nodes can be trained in shorter time, and the output of the method is a trained support vector machine which can be used in further technical application.”
A method for parallel training a support vector machine using a plurality of processing nodes connected to a network of processing nodes based on a set of training data at one of a said plurality of processing nodes, comprising the steps of:
a) selecting a local working set of training data on said one processing node based on local datasaid set of training data;
b) transmitting selected data related to said local working set of training data from said one processing node to said network;
c) receiving an identification of a global working set of training data sent by said network on said one processing node;
d) optimizing said global working set of training data on said one processing node by executing a quadratic function;
e) updating a portionnumber of gradients of said global working set of training data on said one processing node; and
f) repeating said steps a) through e) until a convergence condition is met.
The examiner disagreed with the applicant’s above reply, and alleged that the technical problem referred to in the applicant’s reply could not be solved by the technical solution described in the currently amended claim 1.
In response, the applicant submitted the following two different amendments to claim 1. As for Solution (1), the examiner held that such amendments as “via a processor” and “via a network” are not supported by the original application documents. As for Solution (2), judging from the subsequent examination history, the examiner accepted Solution 2 and continued to examine the inventive step of the application documents.
Solution (1):
A method for training a support vector machine based on a set of training data at one of a plurality of processing nodes, comprising the steps of:
a) selecting, via a processor of a first processing node, a local working set of training data based on local training data stored in a memory of the first processing node;
b) transmitting, via a network interface of the first processing node, certain gradients to a second processing node, the certain gradients selected data related to said local working set from gradients of the working set of training data;
c) receiving at the network interface of the first processing node an identification of a global working set of training data;
d) executing, via the processor of the first processing node, a quadratic function stored in a storage device of the first processing node to optimizeoptimizing said global working set of training data;
e) updating a portion of gradients of said global working set ofthe training data stored in the memory of the first processing node; and
f) repeating said steps a) through e) until a convergence condition is met.
Solution (2):
A computer-implemented method for parallel training a support vector machine using a plurality of processing nodes connected to a network of processing nodes based on a set of training data at one of a plurality of processing nodes, each of the processing nodes stores a subset of a kernel matrix only, comprising the steps of:
a) at each of the plurality of processing nodes, selecting a local working set of training data based on local data said set of training data;
b) at each of the plurality of processing nodes, transmitting selected data related to said local working set of training data to said network, said selected data comprising gradients of said local working set of training data;
c) at each of the plurality of processing nodes, receiving an identification of a global working set of training data selected, at said network, based on the data transmitted from the plurality of processing nodes, said identification being sent by said network;
d) at each of the plurality of processing nodes, optimizing said global working set of training data by executing a quadratic function;
e) at each of the plurality of processing nodes, updating a portionnumber of gradients of said global working set of training data, the step of updating comprising computing the subset of the kernel matrix; and
f) repeating said steps a) through e) until a convergence condition is met, the convergence condition being the Karush-Kuhn-Tucker condition.
Example 2 (EP3291146A):
A method for use with a convolutional neural network-CNN-used to classify input data, the method comprising:
after input data has been classified by the CNN, carrying out a labeling process in respect of a convolutional filter of the CNN which contributed to classification of the input data, the labeling process comprising inputting an output of the convolutional filter, and/or an output of a max-pooling filter associated with the convolutional filter, into a filter classifier which employs an input data classification process to assign a label to a feature of the input data represented by the convolutional filter;
repeating the labeling process in respect of each individual convolutional filter of the CNN which contributed to classification of the input data;
translating the CNN into a neural-symbolic network in association with the assigned labels;
using a knowledge extraction method to extract from the neural-symbolic network knowledge relating to the classification of the input data by the CNN; and
generating and outputting at least one of: a summary comprising the input data, the classification of the input data assigned by the CNN, and the extracted knowledge; and an alert indicating that performance of an action or task, using the extracted knowledge and classified input data, is required.
Analysis:
This application involves an algorithm for neural network to classify data filed in 2003, which is an improvement to the algorithm. During the examination of the original application documents, the EESR alleged that, “Claim 1 is directed to an abstract method based on the use of certain mathematical or abstract models (a convolutional neural network, filter classifier, neural-symbolic network). The claim does not specify any technical means whatsoever to perform the steps. The few terms that might be interpreted as technical features (such as alert) are also not further specified and technically characterised.” The applicant did not make a reply to the EESR, which means, the application did not enter the subsequent substantive examination stage.
Example 3 (EP1546948A2):
A method of simulating movement of an autonomous entity through an environment, the method comprising:
providing a provisional path through a model of the environment from a current location to an intended destination;
providing a profile for said autonomous entity;
determining a preferred step towards said intended destination based upon said profile and said provisional path;
determining a personal space around said autonomous entity;
determining whether said preferred step is feasible by considering whether obstructions infringe said personal space.
Analysis:
This application involves a method for computer simulation filed in 2003. During the examination, the examiner alleged that the simulation model has no technical character, and its implementation on the computer was obvious. In the subsequent appeal phase, the appellant raised the following questions:
(1) In the assessment of inventive step, can the computer-implemented simulation of a technical system or process solve a technical problem by producing a technical effect which goes beyond the simulation’s implementation on a computer?
(2) If the answer to the first question is yes, what are the relevant criteria for assessing whether a computer-implemented simulation claimed as such solves a technical problem?
(3) What are the answers to the first and second questions if the computer-implemented simulation is claimed as part of a design process, in particular for verifying a design?
The appellant’s arguments can be summarized as follows: the application concerned modeling pedestrian movement, which could be used to help design or modify a venue, and it sought a more accurate and realistic simulation of pedestrian crowds in real-world situations, which could not be adequately modeled by conventional simulators.
The Board of Appeal handed over the above questions, namely how to assess the inventive step of an invention of computer simulation, to the EU Enlarged Board of Appeal (EBA). EBA made a decision on March 6, 2012, and answered the above questions as follows:
1. In order to assess the inventive step, the computer-implemented simulation in a technical system or process can solve technical problems by producing technical effects that exceed those produced by such simulation on computers;
2. For this assessment, the technical principle of simulation to be based entirely or partly on the simulation system or process is not a sufficient condition;
3. If computer-implemented simulation is claimed to be part of the design process, especially to be used for verifying the design, the answers to the first question and the second question will be no different.
(See:https://www.epo.org/law-practice/case-law-appeals/recent/t140489ep1.html)
Example 4 (EP1257904B1):
A computer-aided method for numerical simulation of a circuit with a step width δ, and which is subject to 1/f noise influences,
in which the circuit is described by a model (1) which has input channels (2), noise input channels (4) and output channels (3),
in which the behavior of the input channels (2) and of the output channels (3) is described by a system of differential equations or algebraic-differential equations,
in which an output vector (OUTPUT) is calculated by 1/f-distributed random numbers for an input vector (INPUT) present on the input channels (2), and for a noise vector (NOISE) y present on the noise input channels (4), and
in which the noise vector y is generated by the following steps:
determining a desired spectral value P of the 1/f noise,
determining a value n for the number of the random numbers, to be generated, of a 1/f noise,
determining an intensity constant const,
forming a covariance matrix C of dimension (n × n), one element e(i, j) each of the covariance matrix C being determined using the following equation:
e(i, j) = const ⋅ δ β + 1 ⋅ i - j + 1 β + 1 - 2 i - j β + 1 + i - j - 1 β + 1, where i, j = 1, ..., n
forming the Cholesky decomposition L of the covariance matrix C,
the following steps being carried out for each sequence, to be generated, of random numbers of a 1/f noise:
forming a vector x of length n from random numbers normally distributed in (0,1), and
generating a vector y of length n of the desired 1/f-distributed random numbers by multiplying the Cholesky decomposition L by the vector x.
Analysis:
This application involves a computer-aided method filed in 2001. During the examination, the original examination department held that claim 1 is excluded from patentability under EPC Art. 52(2) on the ground that the simulation method described in claim 1 constitutes a psychological behavior or mathematical method. However, in the subsequent appeal process, the Board held that, “Simulation of a circuit subject to 1/f noise constitutes an adequately defined technical purpose for a computer-implemented method functionally limited to that purpose. Specific technical applications of computer-implemented simulation methods are themselves to be regarded as modern technical methods which form an essential part of the fabrication process and precede actual production, mostly as an intermediate step. In that light, such simulation methods cannot be denied a technical effect merely on the ground that they do not yet incorporate the physical end product.”
(See:https://www.epo.org/law-practice/case-law-appeals/recent/t051227ep1.html)
Example 5 (EP2833303A1):
A method for solving multidimensional optimization problems on a set of feasible solutions {S1, ..., Sn} of a discrete combinatorial problem comprising steps of:
calculating optimization values for the set of feasible solutions{S1, ..., Sn}by using a set of optimization functions {f1, ..., fk};
calculating mean values µ(fi) to the set of optimization functions {f1, ..., fk}according to
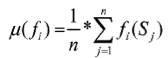
calculating standard deviation values s(f) to the set of optimization functions {f1, ..., fk} according to
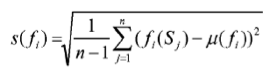
normalize the optimization values for the set of feasible solutions {S1, ..., Sn} according to
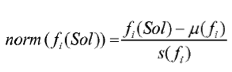
accumulate the normalized optimization values norm (fi(Sol) ) according to
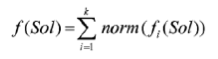
find a minimum for the accumulated normalized optimization values
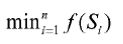
Analysis:
This application involves an optimization algorithm filed in 2013. During the examination, the examiner alleged that a computer implementation is neither explicitly specified in claim 1, nor could it be acknowledged as being implicit from the present wording of claim 1; throughout the whole application, the claimed method is presented as an abstract method without any condition of being “computer-implemented”, and no computer implementation is defined; in addition, a complex formulation of the optimization problem is not sufficient to imply that the method must be computer-implemented. The Board held that if the use of computer means were indeed indispensable, it would have been necessary to include the computer implementation as an essential feature in the claimed method. In addition, a complex formulation of the optimization problem is not sufficient to imply that the method must be computer-implemented.
(See:https://www.epo.org/law-practice/case-law-appeals/recent/t161820eu1.html)
Suggestions on Drafting
It can be seen from the foregoing examples that EPO is relatively strict in the patentability of patents involving AI algorithms. In the practice of examination, based on the principle of determining whether the claimed subject-matter has a technical character as a whole, the drafting of a claim needs to be able to reflect that the mathematical method may contribute to producing a technical effect that serves a technical purpose, by its application to a field of technology and/or by being adapted to a specific technical implementation. For example, the technical features defined in the claim should reflect that the method must be implemented by a computer or serve a sufficiently-defined technical purpose.
3.4 AI-related Patent Practice in Japan
This section will introduce the patent practice related to AI under the Japanese Patent Law.
3.4.1 Revision schedule for important normative documents related to AI invention examination
The Japan Patent Office (JPO) attaches great importance to AI-related patent examination, and issued relevant examination standard changes and case guidelines in 2018, 2019 and 2021, as shown in the following table.

3.4.2 Major Provisions of the Japanese Patent Law Considered at the Right Acquisition Stage
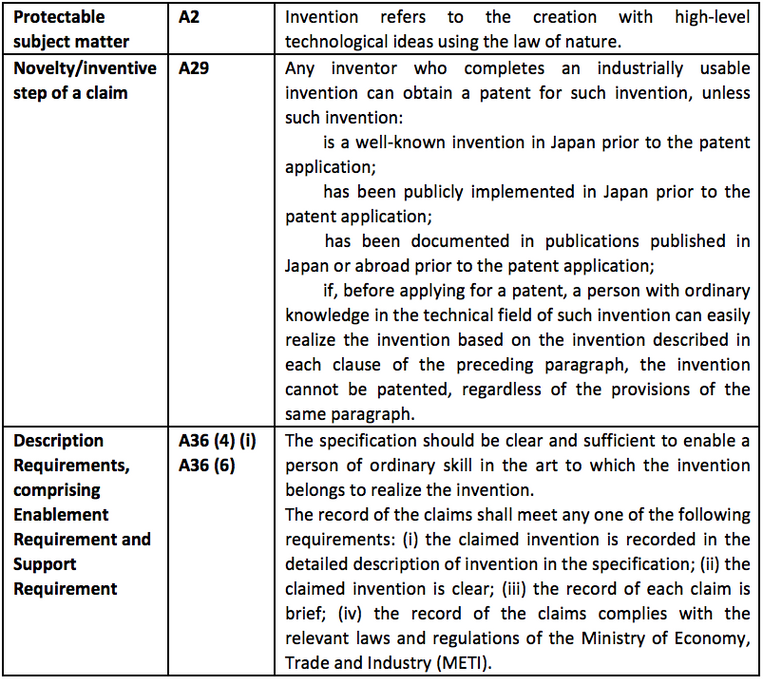
3.4.3 Subject Matter Eligibility
(1) Two-Step Approach
JPO stipulates a two-step approach to judge the subject matter eligibility:
The first step is the common criteria, that is, invention is the creation with high-level technological ideas using the law of nature;
the second step is the special criteria for inventions related to computer software, which proceeds according to the concepts based on software viewpoint.
In the first step, if the invention is considered to be mathematical formulas, human mental activities, subjective arrangements (such as the rules of playing games), simple information expression, etc., it will be ineligible. Inventions related to computer software will be considered to be eligible if device control or processing related to control is concretely performed, or information processing is concretely performed based on technical characteristics such as physical, chemical, biological, or electrical properties of an object, without necessity to proceed according to the concepts based on software viewpoint in the second step; if it is not possible to determine whether they are eligible, then it is necessary to make judgment in the second step. In the second step, if the information processing through software is realized through hardware resources, or the processor or its operating method is operated in cooperation with software and hardware resources, such inventions are considered to be eligible.
It can be seen from the above that JPO has a relatively high tolerance for subject matter eligibility, and AI-related programs, data structures, models, etc. meet the eligibility requirements under certain conditions. Specifically, in addition to the protectable subject matter of storage media currently recognized in China’s patent examination practice, Japan has further recognized the protectable subject matter of inventions related to computer software such as programs, data, data structures, and machine learning models that meet certain conditions. In more detail, the use of hardware resources to concretely realize software-based information processing, the information processing device that works in association with the software, its working method, and the storage media for recording the software can all be considered to be a creation with high-level technological ideas using the law of nature. Among them, software-related protectable subject matters such as programs, data structures, and machine learning models related to AI technology can be considered to meet the requirement for subject matter eligibility, provided that the record of their claims can clearly specify computer-based information processing. However, if the data to be protected is only a simple expression of information, and there is no stipulation regarding computer-based information processing, it still doesn’t meet the requirement for subject matter eligibility.
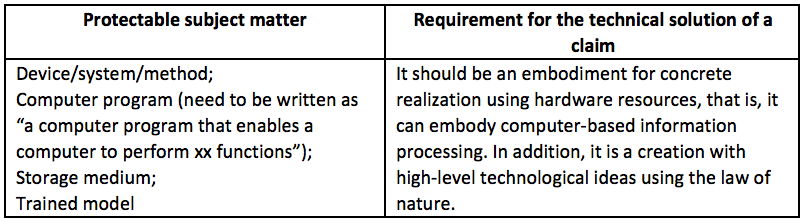
(2) Case Example
[Example 1]:
A trained model for causing a computer to function to output quantified values of reputations of accommodations based on text data on reputations of accommodations, wherein;
the model is comprised of a first neural network and a second neural network connected in a way that the said second neural network receives output from the said first neural network;
the said first neural network is comprised of an input layer to intermediate layers of a feature extraction neural network in which the number of neurons of at least one intermediate layer is smaller than the number of neurons of the input layer, the number of neurons of the input layer and the number of the output layer are the same, and weights were trained in a way each value input to the input layer and each corresponding value output from output layer become equal;
weights of the said second neural network were trained without changing the weights of the said first neural network; and
the model causes the computer function to perform a calculation based on the said trained weights in the said first and second neural networks in response to appearance frequency of specific words obtained from the text data on reputations of accommodations input to the input layer of the said first neural network and to output the quantified values of reputations of accommodations from the output layer of the said second neural network.
Analysis:
JPO holds that the main content of this application is to use neural networks to process text information and make analysis based on the appearance frequency of specific words obtained from the text data on reputations of accommodations. The core of the claims is a computer program. The JPO considers such a technical solution as a patentable subject matter in the JPO Examination Guidelines for Patentability on the grounds that the information processing of the software is concretely realized through the use of hardware resources. Therefore, the trained model of claim 1 is a creation with technological ideas using the law of nature, and is thus an “invention”.
(3) Suggestion on Drafting
It is recommended to record the examples used to protect different subject matters in multiple dimensions. Specifically, in addition to the subject matters of the claims that are also recognized by China’s domestic examination practice, it is recommended that the software-related protectable subject matters such as programs, data structures, and machine learning models be further added in the specification based on the key points of protection and implementation forms of AI technology so as to enable applicants to obtain a more comprehensive scope of protection in Japan in multiple dimensions.
3.4.4 Inventive step
(1) Examination on inventive step
According to the provisions of the JPO Examination Guidelines for Patentability, the specific steps to determine whether a patent application involves an inventive step include:
1) Understanding the claimed invention;
2) Finding a comparison document that is most similar to the present invention;
3) Comparing the present invention with the comparison documents to find the same technical features and distinct technical features;
4) Reasoning for distinct technical features.
The reasoning part includes:
1) First consider whether the distinct technical feature is a technical innovation easily thought of by those skilled in the art, such as: selection of the most suitable material from the known materials, optimization of the numerical range, replacement of equivalents, technical changes in specific applications, content recognized by the applicant, etc.; if the distinct technical feature is not a technical innovation easily thought of by those skilled in the art, the present invention involves an inventive step;
2) If the distinct technical feature is a technical innovation easily thought of by those skilled in the art, continue to discuss whether there is a motivation, for example, whether the comparison document and the present application have: A. relevance in the technical field, B. commonality in the subject, C. commonality in the function and role, D. whether the cited invention has enlightenment, or belongs to common knowledge (any single item in the above A-D can be considered as a motivation); if there is no motivation, the present invention involves an inventive step;
3) If there is motivation, continue to discuss whether there are elements that deny the above logical reasoning, for example: A. obstacle factors (different cited documents cannot be combined due to technical obstacles therein), B. advantageous invention effect, C. commercial success, long-term pending subjects, etc., among which the obstacle factors are the key to answering questions about inventive step.
According to the Examination Guidelines, general principles are applied to the judgment of the inventive step of AI inventions, and technical features and non-technical features are not distinguished, but all the features recorded in the claims should be considered. In particular, according to the examples provided in the Examination Guidelines, the main dimensions for judging whether an AI-related patent application meets the requirement for inventive step include:
1) Is “human behavior” systematized only using AI technology;
2) Is it simply an improved method of predicting the output result based on the input data;
3) Is the change to training data used for machine learning just a combination of known data without significant effects;
4) Is it preprocessing of training data for machine learning?
Specifically,
a) AI inventions will be considered not to involve an inventive step if AI is simply used to transform manually-operated tasks into computerized processing or to systematize known methods, in other words, if it is an invention that simply uses AI technology to systematize the processing performed by humans (e.g., formulas and operating methods manually calculated by humans) and make it processed by computers, or the prediction method used to generate prediction results based on original input data is simply changed from existing technology to AI technology, it is often considered that the above improvement is predictable by those skilled in the art, and the inventive step will not be recognized;
b) If beneficial effects can be obtained through the selection/change of input data, the invention is considered to involve an inventive step; on the contrary, if the selection/change of input data is only a combination of known data that does not achieve beneficial effects, the invention doesn’t involve an inventive step. In other words, due to the possibility of generating data noise when using data with unclear correlation to change training data (such as adding data into input data), if the present invention can produce unpredictable and significant technical effects by changing the training data, its inventive step will be recognized; on the contrary, if the change to the training data is only a combination of related data that can be predicted by those skilled in the art and does not produce significant technical effects, the inventive step will not be recognized;
c) If the preprocessing of the input data is not disclosed and can produce beneficial effects, the invention is considered to involve an inventive step, otherwise it is not. In other words, changing the form of the training data to improve the accuracy of the target output data by performing certain preprocessing on the training data used as input will be considered as a simple design change, and inventive step will not be recognized. However, if the preprocessing of training data is not disclosed in the prior art and has produced significant technical effects, the inventive step can be recognized.
(2) Case Examples
[Example 1]
A cancer level calculation apparatus that calculates a possibility that a subject person has cancer, using a blood sample of the subject person comprising:
a cancer level calculation unit that calculates a possibility that a subject person has cancer, in response to an input of measured values of A marker and B marker that have been obtained through blood analysis of the subject person,
the cancer level calculation unit including a neural network that has been trained through machine learning using training data to calculate an estimated cancer level in
response to the input of the measured values of A marker and B marker.
Analysis:
JPO holds that such claim lacks an inventive step on the grounds that there are such solutions in the prior art: a cancer level calculation apparatus that calculates a possibility that a subject has cancer, using a blood sample of the subject, comprising a step that calculates a possibility that a subject has cancer, in response to an input of measured values of A marker and B marker that have been obtained through blood analysis of the subject. In the field of machine learning, a trained neural network is used to calculate the possible that a subject has a certain disease based on the subject’s data input. The input data may be human biological data, and the output data is on the possibility of having a disease, both of which are well-known, so the patent lacks an inventive step.
It shows that, in accordance with the JPO Examination Guidelines for Patentability, for the invention combining technical features with AI algorithms, i.e. the invention using AI algorithms to solve technical problems, if the relevant technical means are known, the AI algorithms used are also known, only known algorithms are applied to new scenes, and neither algorithms nor technical means have been improved, such patent lacks an inventive step.
[Example 2]
A dementia stage estimation apparatus comprising:
a speech information obtainment means for obtaining a speech information on a conversation between a questioner and a respondent;
a speech information analysis means for analyzing the speech information, and then specifying a speech section by the questioner and a speech section by the respondent;
a speech recognition means for converting, through speech recognition, the speech information on the speech section by the questioner and the speech section by the respondent into text and then outputting a character string;
a question topic specification means for specifying a question topic by the questioner based on the result of the speech recognition; and
a dementia stage determination means for inputting, to a trained neural network, the question topic by the questioner and the character string of the speech section by the respondent to the question topic in an associated manner with each other, and then determining a dementia stage of the respondent,
wherein the neural network is trained through machine learning using training data so as to output an estimated dementia stage, in response
to an input of the character string of the speech section by the respondent in an associated manner with the question topic by the questioner.
Analysis:
The prior art document involves a dementia stage estimation apparatus, comprising: a speech information obtainment means for obtaining a speech information on a conversation between a questioner and a respondent; a speech recognition means for converting, through speech recognition, the speech information into text and then outputting a character string; and a dementia stage determination means for inputting, to a trained neural network, the character string that has been converted into text by a speech recognition means, and then determining a dementia stage of the respondent, wherein the neural network is trained through machine learning using training data so as to output an estimated dementia stage, in response to an input of the character string.
JPO holds that the patent involves an inventive step compared to the prior art because those skilled in the art modify the training data through certain preprocessing. This training data is the input of the neural network used for machine learning in order to improve the estimation accuracy of the neural network. Such technical feature is not disclosed in the prior art, and the technology of inputting, to a trained neural network, the question topic by the questioner and the character string of the speech section by the respondent to the question topic in an associated manner with each other, and then determining a dementia stage of the respondent is not a technical common sense either. The invention of claim 1 brings about a remarkable effect, that is, by associating the question topic by the questioner and the answer (corresponding character string) by the respondent, a highly accurate estimation of the dementia stage can be carried out.
The key reason why this application involves an inventive step lies in the preprocessing of the training data, associating the question topic by the questioner with the character string of the answer by the respondent. This association is not disclosed in the prior art, even though the prior art has disclosed the technical solution of estimating dementia stage using neural networks, the invention still involves an inventive step.
Based on the analysis of the above two examples, it can be concluded that if a technical solution in the AI field needs to involve an inventive step, it must be improved in the following two aspects: (1) there are technical or algorithmic features that are not easy to predict by those skilled in the art, which can be expressed as preprocessing of training data; (2) there are new improvements in the algorithm. However, the invention that only applies the known algorithm to the new scene, with the known technical means used in the related scene, and predictable technical effect obtained, lacks an inventive step.
(3) Suggestion on Drafting
When describing the training data of the present invention in the specification, try to determine the beneficial technical effects of each correlation. Furthermore, in terms of the change in the correlation caused by the change of the training data, further define the significant technical effect produced by the changed correlation compared to the original correlation. In addition, in terms of optimizing the preprocessing of training data, further describe the changes in the correlation and significant technical effects caused by the optimization of the preprocessing. In addition, in terms of the change of correlation and that caused by the optimization of preprocessing, supplemental describe the breakthrough point of the change compared to the conventional means, and thus provide a sufficient basis for argumentation for inventive-step examination during substantive examination.
3.4.5 Insufficiency of Disclosure and Specification Support
(1) Description Requirements
The so-called Description Requirements comprise “Enablement Requirement” and “Support Requirement”. The “Enablement Requirement” is similar to the provisions of Article 26.3 of the Patent Law of the People’s Republic of China regarding the full disclosure of the specification, which requires a clear and full description of the present invention in the specification to the extent that those skilled in the art can implement it. The “Support Requirement” is similar to the provisions of Article 26.4 of the Patent Law of the People’s Republic of China regarding the basis of the specification, which requires the invention claimed by the claims shall not exceed the scope of the detailed description of the invention in the specification.
JPO holds that in AI-related technical fields, training data containing multiple types of data for machine learning is usually used, which generally must meet the following two conditions, that is, based on the disclosure in the specification, it can be recognized that there is a certain relationship, such as the correlation between multiple types of data, or based on general technical knowledge, it can be inferred that there are relationships between multiple types of data. That is to say, the specification generally discloses the relevance between input data and output data, unless the relevance of such data can be inferred by those skilled in the art.
Therefore, the key to judging whether an AI-related application meets the “Enablement Requirement” and “Support Requirement” lies in: whether the correlation between multiple types of data used for AI machine learning, that is, relevance, is clear, wherein “whether is clear” includes whether the applicant has described it with enough information in the application document, or whether it can be easily clarified by those skilled in the art. According to the examples disclosed by JPO, the above-mentioned correlation can be clarified in the following ways, that is, the existence of correlation between multiple types of data can be proved in the following ways:
1) Directly and concretely record the correlation between multiple types of data in the specification;
2) Directly prove the correlation between multiple types of data through description or statistical analysis in the specification;
3) In the specification, perform performance evaluation on the formed AI algorithm model, and indirectly prove the correlation between multiple types of data according to the results of the performance evaluation;
4) Although the specification does not record or prove the correlation between multiple types of data, those skilled in the art can reasonably infer the existence of the correlation based on the technical common sense at the time of application.
In addition, special attention needs to be paid to:
a) For an invention of products that are predicted to have a certain function through AI, for example, under the circumstance that the prediction result is obtained through the prediction of the AI algorithm model, if the prediction accuracy of the AI algorithm model is not tested, in the patent examination practice in Japan, it is usually considered that the prediction result of the AI algorithm model is not an evaluation of the actually manufactured product and cannot replace the same. Therefore, it will be deemed that the description of the specification does not meet the “Enablement Requirement”;
b) When individual types of data in the training data are summarized by a broader concept in the claim for the purpose of obtaining greater scope of protection, if the correlation between individual types of data in training data is only recorded in the specification, but the correlation related to the data that is summarized by a broader concept is not recorded, the correlation between the broadly summarized data may not be supported by the specification.
(2) Analysis of Examples in Practice
[Example 1]
A sugar content estimation system comprising:
a storage means for storing face images of people and sugar contents of vegetables produced by the people;
a model generation means for generating a determination model through machine learning, to which a face image of a person is input and from which a sugar content of a vegetable produced by the person is output, using training data containing the face images of the people stored in the storage means and the sugar contents of the vegetables,
a reception means for receiving an input of an face image; and
a processing means for outputting, using the generated determination model that has been generated by the model generation means, a sugar content of a vegetable produced by a person that is estimated based on the face image of the person inputted to the reception means.
Analysis:
JPO holds that this patent application only indicates there is a specific correlation between “a face image of a person” and “a sugar content of a vegetable produced by the person”, but it does not clearly specify or elaborate on this correlation, and those skilled in the art cannot clarify the connection between the two at the time of application. That is, the correlation between the two types of data (input data and output data) used for AI machine learning is not clear. Therefore, claim 1 of this patent application does not meet the “Enablement Requirement” in the “Description Requirements”.
[Example 2]:
A body weight estimation system comprising:
a model generation means for generating an estimation model that estimates a body weight of a person based on a feature value representing a face shape and a body height of the person, through machine learning using training data containing feature values representing face images as well as actual measured values of body heights and body weights of people;
a reception means for receiving an input of a face image and body height of a person;
a feature value obtainment means for obtaining a feature value representing a face shape of the person through analysis of the face image of the person that has been received by the reception means; and
a processing means for outputting an estimated value of a body weight of the person based on the feature value representing the face shape of the person that has been received by the feature value obtainment means and the body height of the person that has been received by the reception means, using the generated estimation model by the model generation means.
The body weight estimation system as in Claim 1, wherein the feature value representing a face shape is a face-outline angle.
Analysis:
JPO holds that this patent application only describes the correspondence between the face-outline angle of the human face and the body weight, and it is impossible to determine the relationship between other types of facial feature data and the body weight through the application documents. Therefore, claim 1 of this patent application does not meet the “Support Requirement”, while claim 2 does.
(3) Suggestion on Drafting
In order to meet the “Enablement Requirement” as much as possible, it is recommended to clarify the correspondence between the various types of data in the training data in a hierarchical manner. Specifically, for each of the various types of data that constitute the training data, while clearly distinguishing the data summarized by broader and narrower concepts, further specifically clarify the correspondence between the data summarized by broader and narrower concepts and other data summarized by broader and narrower concepts, and thus to make a sufficient description in the specification to realize the hierarchical layout of the claims from broad to narrow.
In order to meet the “Enablement Requirement” as much as possible, it is recommended to clearly describe the correlation reflected by the correspondence between data. Specifically, for each correspondence, a certain correlation reflected by such correspondence, that is, the correlation between multiple types of data, should be clearly recorded in the specification as far as possible. For the correspondence that is not easy to directly reflect the correlation through text description, it is recommended to use the chart data obtained by statistical analysis of the training data, the performance evaluation result for the AI algorithm model, and the data obtained through other experimental methods to prove directly or indirectly the existence and rationality of correlation. In addition, although it is not necessary to clearly record the correlation that can be reasonably inferred by those skilled in the art based on the technical common sense at the time of application in the specification, it is still recommended to define the same in the specification in the manner described above in response to the difference in the determination of technical common sense by the examiners caused by the difference in the technical environment of various countries, and thus to further provide specification support for the correlation between the various data in the claims.
3.5 AI-related Patent Practice in South Korea
3.5.1 Revision Schedule for Important Normative Documents related to AI Invention Examination

3.5.2 Major Provisions regarding the Acquisition of Patent Rights
The major provisions of the Invention Patent Law of South Korea (Patent Law of South Korea) and Examination Guidelines considered at the right acquisition stage are shown in the following table.
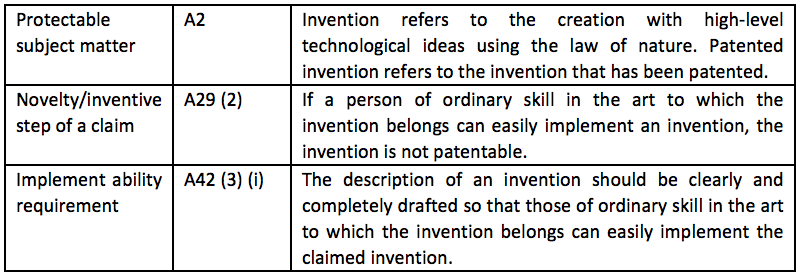
3.6.3 Subject Matter Eligibility
(1) Conditions on Subject Matter
In examining the patented subject matter, South Korea is relatively flexible and lenient. For AI-related inventions, the KIPO Patent Examination Guidelines require that the information processing process of AI can be implemented by hardware. However, in South Korea’s examination practice, the subject matter eligibility of AI-related inventions is not strictly assessed. Technological ideas are more likely to be assessed on the basis of novelty/inventive step rather than eligibility.
The conditions on subject matter of AI-related inventions are equivalent to those of computer-related inventions. Specifically, the subject matter eligibility of AI-related inventions can be judged through the steps shown in the following figure (Source: Examination Standards for Invention and Utility Model Patents (KIPO, 2020.8)).
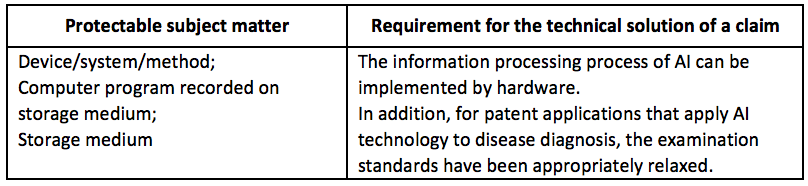
More specifically, in accordance with the Classification of Information and Communication R&D Technology issued by the Ministry of Science, ICT and Future Planning (MSIP) in 2016, AI technology can be classified as shown below [Table 1-1]. According to this Technology Classification Table, AI technology may involve the invention of computer software programs. According to the KIPO Patent Examination Guidelines, software program inventions need to meet the following requirements: “When the software’s information processing process is concretely implemented by hardware, the information processor operating with the software, its operating method, and the computer-readable carrier that records the software can be regarded as a creation with technological ideas using the law of nature. In addition, the specific realization of software information processing by hardware refers to that software is read by computer to operate or process the information that meets the purpose of use through the specific means of software and hardware synergy, so as to realize the specific information processing device or such operation method that meets the purpose of use.”
Therefore, if the information processing of software cannot be realized by hardware, the invention will not belong to a creation with technological ideas using the law of nature. When an AI-related software invention can be realized by hardware, the invention can be recognized as an invention under the Patent Law of South Korea. The scope of software invention includes products, methods, computer-readable carriers recording software programs, and software programs recorded on computer-readable carriers.
In addition, AI-related inventions may involve business method inventions, in which case the invention needs to meet the patentability requirements for general inventions and the said software program requirements.
If an AI-related invention meets the patent standards required for software program invention or business method invention, the invention should also be able to obtain patent rights to protect the interests of the right holders who develop new technologies and reward their contributions, thereby promoting industrial development. According to a similar logic, if the industrial design made by AI meets the patentability requirements set forth in the Industrial Design Protection Law of South Korea, the interests of the right holder of the new design should also be protected and industrial development should be promoted by granting patent rights.
[Table 1-1]
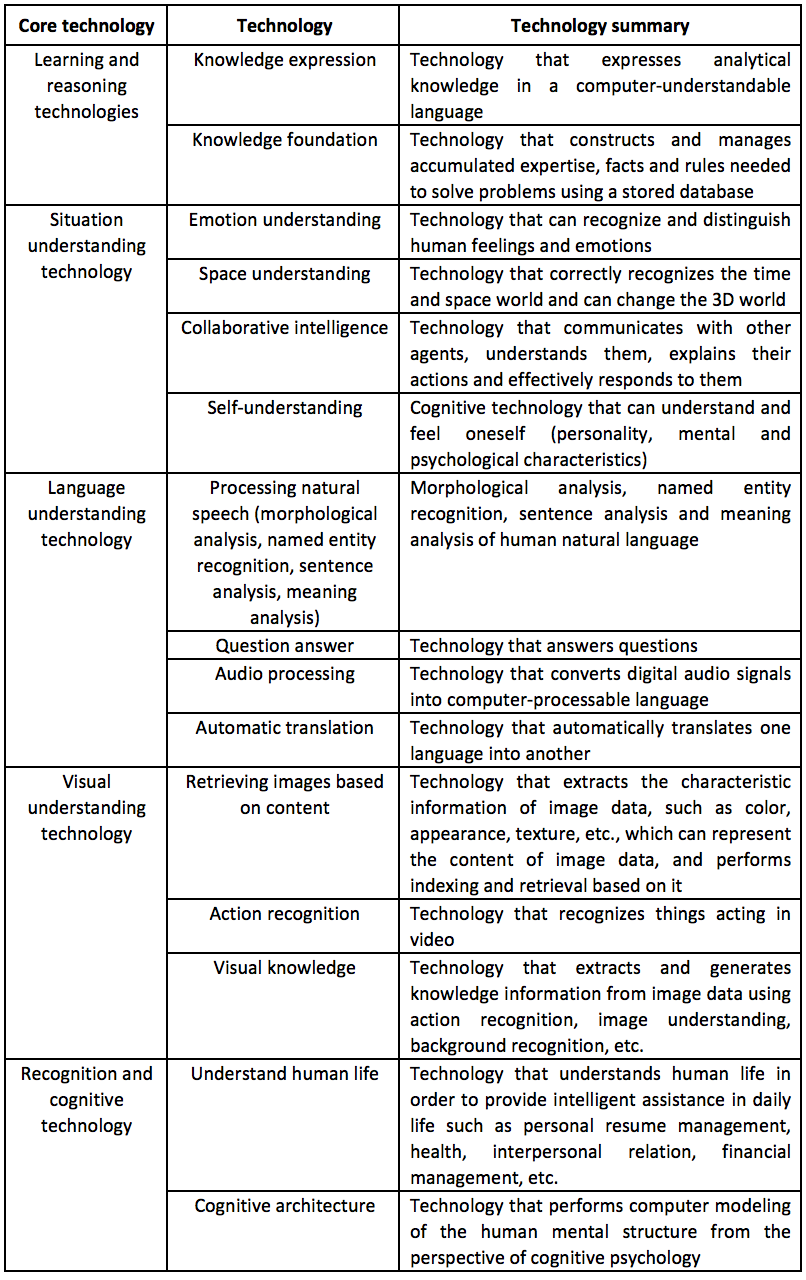
(2) Case Example
2007Hu265 Judgment of the Supreme Court of Korea: “To constitute a business method invention, software-based information processing on a computer is required to be concretely realized by hardware. In addition, while judging whether the claimed invention is an invention using the law of nature, an overall judgment is required in accordance with the claims. Therefore, the invention does not belong to that under the Patent Law if the entire claim is not recognized to use the law of nature, even if a part of the invention described in the claims uses the law of nature.”
2007heo2957 Judgment of the Patent Court of Korea: “The claims of a business method invention should not be the technology using human mental activities, etc. or simply using the general-purpose functions of the computer or the Internet, but the constructed information processing device or such operating method used to concretely implement information processing to achieve a specific purpose after software is read by computer and synergized with hardware. The scope of rights of the business method invention needs to be determined to the extent where the said information processing device or such operating method is constructed. Therefore, in order to claim that the alleged infringing invention belongs to the scope of the rights of the registered business method invention, the alleged infringing invention should include the constituent elements of the patented invention that reflect the characteristics of the said business method invention and the organic combination of the constituent elements.”
Analysis:
If AI-related inventions involve business method inventions, the invention can further meet the requirements for subject matter eligibility of AI invention only when it meets the patentability requirements for a general invention and the conditions required for the relevant software program.
(3) Suggestion on Drafting
It is recommended that when drafting the claims, it is necessary to ensure that the technical solutions recorded in the claims meet the special requirements that the information processing process of AI can be concretely implemented by hardware while ensuring that such solutions meet the general requirements for the patented subject matter (that is, those created using the law of nature). In addition, it is recommended to record the examples for protecting different subjects in multiple dimensions so that the applicant can obtain a more comprehensive scope of protection in South Korea in multiple dimensions.
3.6.4 Inventive step
(1) Examination on Inventive step
According to the relevant provisions of the KIPO Patent Examination Guidelines, the general examination standard for inventive step is: judging whether those skilled in the art can easily obtain the invention involved in the present application based on the comparison documents and common knowledge before the application. For the inventive-step examination of AI-related inventions, the judgment method of computer-related patent applications can be referred to: consider the technical difficulty in the application of related technologies in different fields, whether the common technical problems in the computer field are solved, and whether the common technical effects are obtained in the computer field.
At the same time, KIPO holds that a claim that only describes the use of AI technology is unlikely to be patented unless there are distinctive technical configurations used to solve technical problems (for example, training data, data preprocessing, trained models, loss functions, etc.). Otherwise, the claimed invention will only be regarded as a known AI technology, and this technology can be easily completed by a person of ordinary skill in the art to which the invention belongs to. The said point of view is also applicable to those designs that only use AI technology to systematize or computerize processes that may have been implemented or were previously implemented manually, and simply modify the conventional AI technology (for example, simple change to the trained model) as well as inventions that only add or replace known technologies on the basis of conventional AI technology.
(2) Case Example
Claim:
A method of providing stock information using AI charts that display different colors based on an AI algorithm for judging the rise/fall of stock prices, ...including the steps of displaying different colors based on the algorithm used to identify stock price trends, ...
Analysis:
The standard for judging the rise/fall of stock prices and the method of displaying different colors accordingly are conventional technical means widely used in the field of stock investment or chart analysis, and it is not a creative invention to simply implement such conventional technical means in this field as AI algorithms without defining specific information processing (refer to the 2013HEO1788 Judgment of the Patent Court of Korea).
(3) Suggestion on Drafting
In terms of the requirements for inventive step, KIPO recommends specifying differentiated technical configurations (for example, training data, data preprocessing, trained models, loss functions, etc.), and detailing technical effects that are directly generated by technical configurations and exceed the effects of conventional AI technology, that is, it is necessary to avoid only making conclusive statements about technical effects (such as increasing processing speed, effectively processing massive amounts of data, reducing errors, or providing accurate predictions, etc.). Some drafting skills for the inventive-step requirements are as follows:
1. Invention of AI training data
Provide detailed information on how to process the raw data to obtain training data, for example, describe how to extract features from the input data, and how to generate training data (for example, through standardization, normalization, or vectorization).
Explain the specific effects or improvements that can be derived from data preprocessing (for example, by implementing data preprocessing on closed-circuit television video images related to the “motion tracking” function, the object in the video image can be recognized more accurately because the motion of the object is considered. However, the existing technology only uses the video image to recognize the object).
2. Invention of AI modeling
Describe the specific configuration of modeling, such as the configuration of the training environment, model evaluation, multi-model linkage, parallel or decentralized processing, and optimization of hyperparameters.
Provide the prediction accuracy of training speed and training model, and other effects caused by a specific configuration, with such effects unachievable by conventional AI technology.
3. Invention of AI application
Describe the specific purpose of the output data of the trained model and the effect of using the output data in a specific way, for example, by using the output data of the trained model (such as a label on a car part destroyed in a car accident) to calculate the estimated cost for each repair type, users can easily predict the increase in their insurance premiums based on the repair type they choose.
In addition, it is recommended to draft claims from multiple perspectives (training data, trained models, application services, etc.) to facilitate the determination of infringement. Specifically, for training data, when preprocessing the raw data, the generation method, device, and program storage medium of training data can be used as the defined features in claims, if “the data structure is used to define the processing content executed by the computer”, the data storage medium can also be used as a defined feature in claims; for the trained model itself, where the internal structure of the trained model contains technical features, the method, device, and program storage medium that define the structure of the trained model can be used as the defined features in claims; for the application service, use the method, device, and program storage medium as the defined features in claims.
3.6.5 Sufficiency of Disclosure
(1) Enablement Requirement
In accordance with the Article 42.3.i of the Patent Law of South Korea, the description of an invention should be clearly and completely drafted so that those of ordinary skill in the art to which the invention belongs can easily implement the claimed invention. In terms of AI inventions, KIPO recommends explaining technical problems, solutions, and specific technical configurations (for example, training data, data preprocessing, trained models and loss functions, etc.) so that those of ordinary skill in the art to which the invention belongs can implement the claimed inventions, unless the technical configuration is well known in the art.
In this regard, the specification should specifically record the means for those of ordinary skill in the art to implement AI-related inventions: a) for example, training data, data preprocessing methods, trained models, etc.; b) for example, the correlation between the input data and output data of the trained model; c) a simple description of the well-known trained model (model name, basic structure, source, etc.).
(2) Case Example
Claim 1:
A house temperature automatic control system, comprising:
a storage unit for storing past daily weather data and historical house temperature data;
a trained model generation unit for generating the trained machine model; the said trained machine model uses the temperature from the daily weather data, ..., at least one of the haze concentration data and the said historical house temperature control data as training data;
a collection unit for collecting meteorological information from the server of the China Meteorological Administration; and
an output unit for outputting the house temperature automatic control information predicted by the said current weather information using the said trained machine model.
Specification:
The correlation between the haze concentration data and the house temperature automatic control information is not concretely recorded, and no example that can prove the said correlation is given.
Determination:
The invention described in the claim does not meet the conditions for sufficiency of disclosure/support since it cannot be implemented by those of ordinary skill.
(3) Suggestion on Drafting
The KIPO Patent Examination Guidelines provide some drafting skills for different types of AI inventions, with the details as follows (in order to simplify the description, the AI model training inventions are divided into two categories as follows, that is, “invention of AI training data” used for data preprocessing, and “invention of AI modeling” aiming at constructing machine learning models):
1. Invention of AI Training Data
Describe how to process the raw data to generate, change, add, or delete training data, and the correlation between the raw data and the training data (that is, explain why the raw data is used and why the training data should be preprocessed in some way).
2. Invention of AI Modeling
Specify any technical configuration or method to implement or train the model (for example, if a neural network collection is used to train the model, the neural network used and the process or means of training the model using such neural network should be confirmed).
3. Invention of AI Application
Provide detailed information about the correlation between the input data and output data of the trained model, namely: (1) specify training data; (2) describe the correlation between the characteristics of the training data used to solve the technical problem; (3) use training data or training methods to indicate the machine learning model to be trained; (4) describe how to generate trained models that solve technical problems by using training data and methods.