



点击章节题目阅读其他章节:
第二章 主要国家和地区的人工智能产业政策、知识产权的立体保护和专利申请态势

3.3 欧洲的人工智能专利实务
本节将介绍在欧洲专利法下人工智能(AI)相关的专利实务。
3.3.1与AI相关的EPO审查指南修改
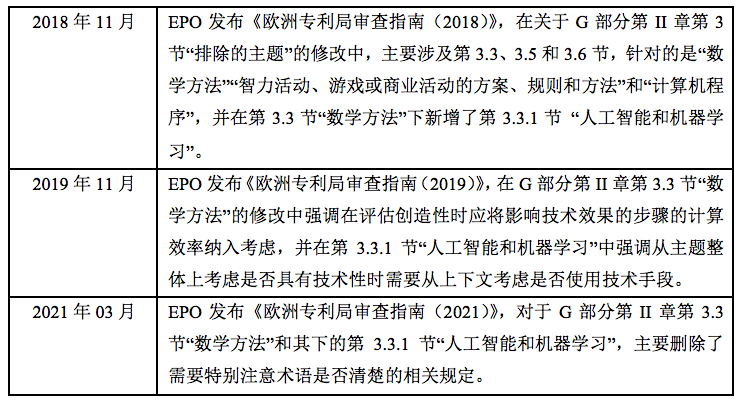
在人工智能技术快速发展的前提下,各国的专利申请数量也相应快速增长。在这种背景下,主要知识产权强国纷纷调整专利审查标准,给出人工智能技术可专利性的判定规则。适应这种需求,欧洲专利局分别于2018年、2019年和2021年多次修改了《欧洲专利局审查指南》,如下表所示。
3.3.2 与专利权的获得相关的EPC主要条款
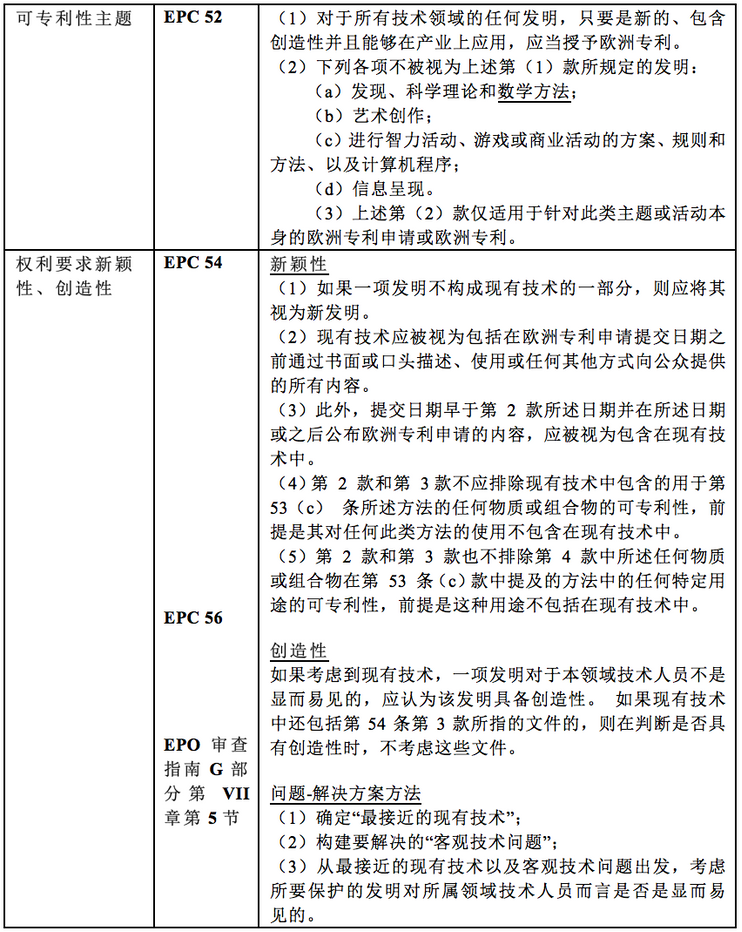
与专利权的获取(包括与人工智能技术相关的专利权获取)所涉及的《欧洲专利公约》(EPC)主要条款如下表所示。
3.3.3关于可专利性
3.3.3.1 EPC 52(1)意义上的“发明”必须具有技术性
EPO审查指南G部分第II章第1节中明确指出:“EPC 52(1)意义上的‘发明’必须是具体的并具有技术性(an "invention" within the meaning of Art. 52(1) must be of both a concrete and a technical character)。” G部分第I章第2节:发明技术性必须达到这样的程度,涉及一个技术领域,与一个技术问题有关,以及在权利要求中存在技术特征(the invention must be of "technical character" to the extent that it must relate to a technical field, must be concerned with a technical problem and must have technical features in terms of which the matter for which protection is sought can be defined in the claim)。
3.3.3.2确定权利要求的主题是否具有技术性的原则
EPO审查指南G部分第II章第3节中规定,在考虑申请的主题是否属于EPC 52(1)意义上的发明时需注意的几个方面:首先,任何依据EPC 52(2)的排除仅适用于针对此类主题本身的申请[EPC 52(3)];其次,将权利要求的主题作为一个整体确定其是否具有技术性,如果不具有技术性,则不属于EPC 52(1)意义上的发明。还必须牢记,是否属于EPC 52(1)意义上的发明的判断独立和区别于工业实用性、新颖性和是否包含创造性步骤的判断。对技术性的评估在不考虑现有技术的情况下进行。
3.3.3.3确定涉及AI的权利要求的主题是否具有技术性的具体说明
根据上述EPC 52(2)和(3)的规定,仅涉及纯粹抽象的数学方法本身不具有可专利性。但是, G部分第II章第3.3节关于“数学方法”的规定,基于从整体上确定所要求保护的主题是否具有技术性这一原则,如果权利要求中使用了技术手段,则其不被EPC 52(2)和(3)规定的可专利性排除,属于EPC 52(1)意义上的发明。根据G部分第II章第3.3.1节的规定,人工智能和机器学习基于计算模型和算法,这些计算模型和算法本身具有抽象的数学性质。因此,指南的G部分第II章第3.3节关于“数学方法”的规定通常也适用于此类计算模型和算法。
通过将数学方法应用于某一技术领域和/或(被)适应于特定的技术实施,数学方法可能对发明的技术性做出贡献,即对服务于技术目的的技术效果做出贡献。
数学方法:
G部分第II章第3.3节给出了数学方法可被认为应用于某一技术领域和/或适应于特定的技术实施的示例。
· 技术目的在技术领域的应用的示例包括:
- 控制特定的技术系统或工艺,例如X射线设备或钢冷却工艺;
- 通过测量压实机所需的经过次数,确定所需材料密度;
- 数字音频、图像或视频的增强或分析,例如去噪、检测数字图像中的人物、估计传输的数字音频信号的质量;
- 语音信号源的分离;语音识别,例如将语音输入映射到文本输出;
- 对数据进行编码(以及相应的解码)以实现可靠和/或有效的传输或存储,例如对于噪音通道中传输数据的纠错编码,压缩音频、图像、视频或传感器数据;
- 加密/解密或签署电子通讯;在RSA加密系统中生成密钥;
- 优化计算机网络中的负载分布;
- 通过处理从生理传感器获取的数据,确定受试者的能量消耗;从耳温检测器获取的数据推导出受试者的体温;
- 提供基于DNA样本分析的基因型评估,并提供该评估的置信区间以量化其可靠性;
- 通过处理生理测量的自动化系统提供医学诊断;
- 在技术相关条件下模拟充分定义的技术项目类别或特定技术过程的行为(参见G部分第II章第3.3.2节)。
· 适应于特定技术实施的示例包括:
- 利用与计算机硬件字长匹配的字长偏移而做出的多项式缩减算法的调整。
人工智能和机器学习:
G部分第II章第3.3.1节给出了人工智能和机器学习的技术应用示例的示例。
· 人工智能和机器学习的技术应用示例包括:
- 在心脏监测设备中使用神经网络来识别不规则的心跳做出了技术贡献;
- 基于低级特征(例如图像的边缘或像素属性)的数字图像、视频、音频或语音信号的分类是分类算法的进一步典型技术应用。
(2)实例分析
例1(EP1770612B1):
A computer-implemented method for parallel training a support vector machine using a plurality of processing nodes and a centralized processing node connected to a network of processing nodes based on a set of training data, each of the processing nodes stores a subset of a kernel matrix only, comprising the steps of:
a)at each of the plurality of processing nodes, selecting a local working set of training data based on said set of training data;
b)at each of the plurality of processing nodes, transmitting selected data related to said local working set of training data to said centralized processing node, said selected data comprising gradients of said local working set of training data;
c)at each of the plurality of processing nodes, receiving an identification of a global working set of training data selected, at said centralized processing node, based on the data transmitted from the plurality of processing nodes, said identification being sent by said centralized processing node;
d)at each of the plurality of processing nodes, optimizing said global working set of training data by executing a quadratic function;
e)at each of the plurality of processing nodes, updating a subset of gradients of said global working set of training data, the step of updating comprising computing the subset of the kernel matrix, wherein said subset of gradients corresponds to said subset of the kernel matrix; and
f)repeating said steps a)through e)until a convergence condition is met, the convergence condition being the Karush-Kuhn-Tucker condition.
译文如下:
1. 一种计算机实现的方法,用于使用多个处理节点并行地训练支持向量机,以及基于一组训练数据连接到处理节点的网络的集中处理节点,所述处理节点的每个存储核矩阵的子集,包括以下步骤:
a)在多个处理节点中的每个,基于所述训练数据集选择训练数据的本地工作集;
b)在多个处理节点中的每个,将与所述本地工作训练数据集相关的所选数据发送到所述集中处理节点,所述选择的数据包括所述本地工作训练数据集的梯度;
c)在多个处理节点中的每个,在所述集中处理节点处,基于从多个处理节点发送的数据,接收所选择的全局工作训练数据组的标识,所述标识由所述集中处理发送节点;
d)在多个处理节点中的每个,通过执行二次函数来优化所述全局工作训练数据集;
e)在多个处理节点中的每个,更新所述全局工作训练数据集的梯度子集,更新步骤包括计算核矩阵的子集,其中所述梯度子集对应于所述核矩阵的子集;以及
f)重复所述步骤a)至e)直到满足收敛条件,收敛条件为Karush-Kuhn-Tucker条件。
分析:
该申请为2006年提交的关于支持向量机的算法,属于对算法的改进,并未涉及到传统意义上的“技术特征”,该申请2016年在欧洲获得授权。以下为审查过程的简要描述:
在对于原始申请文件(EP1770612)的审查过程中,EESR中曾指出该方法的特征没有能够被审查员确定的技术效果,具体而言,该方法的输出没有被用于任何技术应用,权利要求1不具有技术特征,仅是数学方法。原始权利要求1具体如下:

申请人对权利要求1进行了如下修改并提出了实审请求,同时在提交的关于EESR的答复中争辩了:在处理节点的网络上运行的支持向量机可以在较短的时间内被训练好,该方法的输出是一个训练好的支持向量机,训练好的支持向量机能够用于技术应用。

审查员不认可申请人的上述答复,并认为申请人在答复中提到的技术问题并不能通过当前的权利要求1所表述的技术方案解决。
对此,申请人提交了针对权利要求1的以下两种不同修改方案。对于方案1,审查意见认为“通过处理器”、“通过网络”等修改得不到原申请文件的支持;对于方案2,根据后续审查历史判断,审查员认可了该修改方案,并继续就申请文件的创造性进行审查。
方案(1):

方案(2):

例2(EP3291146A):
A method for use with a convolutional neural network-CNN-used to classify input data, the method comprising:
after input data has been classified by the CNN, carrying out a labelling process in respect of a convolutional filter of the CNN which contributed to classification of the input data, the labelling process comprising inputting an output of the convolutional filter, and/or an output of a max-pooling filter associated with the convolutional filter, into a filter classifier which employs an input data classification process to assign a label to a feature of the input data represented by the convolutional filter;
repeating the labelling process in respect of each individual convolutional filter of the CNN which contributed to classification of the input data;
translating the CNN into a neural-symbolic network in association with the assigned labels;
using a knowledge extraction method to extract from the neural-symbolic network knowledge relating to the classification of the input data by the CNN; and
generating and outputting at least one of: a summary comprising the input data, the classification of the input data assigned by the CNN, and the extracted knowledge; and an alert indicating that performance of an action or task, using the extracted knowledge and classified input data, is required.
译文如下:
1. 一种用于卷积神经网络(CNN)对输入数据进行分类的方法,包括:
在CNN对输入数据进行分类之后,对所述CNN的卷积滤波器执行标记处理,所述标记处理有助于输入数据的分类,所述标记处理包括将卷积滤波器的输出和/或与卷积滤波器相关联的最大池滤波器的输出,输入到滤波器分类器中,所述滤波分类器采用输入数据分类处理,以将标签分配给由卷积滤波器表示的输入数据的特征;
重复关于CNN有助于输入数据的分类的每个单独卷积滤波器的标记过程;
将CNN转换为与指定标签相关联的神经符号网络;
使用知识提取方法从与CNN对输入数据的分类有关的神经符号网络知识中提取;以及
生成并输出以下中的至少一个:包括输入数据的摘要、由CNN分配的输入数据的分类、以及提取的知识,并且请求使用提取的知识和分类的输入数据来指示动作或任务的执行的警报。
分析:
该申请为2003年提交的关于神经网络进行数据分类的算法,属于对算法的改进。在对于原始申请文件的审查过程中,EESR中指出:权利要求1是基于使用一定数学或抽象模型(卷积神经网络、滤波分类器、神经符号网络)的一种抽象方法,权利要求的步骤执行未规定任何的技术手段,极少的术语可以被解释为技术特征(例如警报),并且也没有进一步的技术特征限定。申请人没有对该EESR进行答复,也即,该申请没有进入后续实审阶段。
例3(EP1546948A2):
A method of simulating movement of an autonomous entity through an environment, the method comprising:
providing a provisional path through a model of the environment from a current location to an intended destination;
providing a profile for said autonomous entity;
determining a preferred step towards said intended destination based upon said profile and said provisional path;
determining a personal space around said autonomous entity;
determining whether said preferred step is feasible by considering whether obstructions infringe said personal space.
译文如下:
1. 一种仿真自主实体在环境中移动的方法,该方法包括:
提供通过环境模型从当前位置到预期目的地的临时路径;
提供所述自治实体的概况;
基于所述简档和所述临时路径确定朝向所述预定目的地的优选步骤;
确定所述自治实体周围的个人空间;
通过考虑障碍物是否侵犯所述个人空间来确定所述优选步骤是否可行。
分析:
该申请为2003年提交的关于计算机仿真的方法,在审查过程中,审查意见认为该仿真模型是非技术性的,并且其在计算机上的实现是显而易见的。在后续诉讼阶段,上诉人提出了以下问题:
(1)在创造性评估中,技术系统或过程中通过计算机实现的仿真能否通过产生超出计算机上实施仿真的技术效果来解决技术问题?
(2)如果第一个问题的答案是肯定的,那么评估计算机实现的仿真是否解决了技术问题的相关标准是什么?
(3)如果计算机实现的仿真被称为设计过程的一部分,特别是用于验证设计,那么第一和第二个问题的答案是什么?
上诉人的论点可归纳为:该应用程序涉及对行人运动进行建模,可用于帮助设计或修改场地。它寻求在现实世界中对行人人群进行更准确和逼真的仿真,而传统仿真器无法充分仿真。
上诉委员会将如何评估计算机仿真发明的创造性的上述问题提交给欧盟专利扩大上诉委员会(EBA)。EBA于0201年3月20日做出决定,对上述问题回答如下:
1. 为评价创造性,对技术系统或过程进行计算机实现的仿真,可以通过产生超出仿真在计算机上实现的技术效果来解决技术问题;
2. 对于该评价,仿真完全或部分基于仿真系统或过程的技术原理并不是充分条件;
3. 如果计算机实现的仿真被声称为设计过程的一部分,特别是用于验证设计,那么第一个问题和第二个问题的答案没有什么不同。
(参见: https://www.epo.org/law-practice/case-law-appeals/recent/t140489ep1.html)
例4(EP1257904B1):
A computer-aided method for numerical simulation of a circuit with a step width δ, and which is subject to 1/f noise influences,
in which the circuit is described by a model (1) which has input channels (2), noise input channels (4) and output channels (3),
in which the behavior of the input channels (2) and of the output channels (3) is described by a system of differential equations or algebraic-differential equations,
in which an output vector ( OUTPUT ) is calculated by 1/f-distributed random numbers for an input vector ( INPUT ) present on the input channels (2), and for a noise vector ( NOISE ) y present on the noise input channels (4), and
in which the noise vector y is generated by the following steps:
determining a desired spectral value P of the 1/f noise,
determining a value n for the number of the random numbers, to be generated, of a 1/f noise,
determining an intensity constant const,
forming a covariance matrix C of dimension (n × n), one element e(i, j) each of the covariance matrix C being determined using the following equation:
e(i, j) = const ⋅ δ β + 1 ⋅ i - j + 1 β + 1 - 2 i - j β + 1 + i - j - 1 β + 1, where i, j = 1, ..., n
forming the Cholesky decomposition L of the covariance matrix C,
the following steps being carried out for each sequence, to be generated, of random numbers of a 1/f noise:
forming a vector x of length n from random numbers normally distributed in (0,1), and
generating a vector y of length n of the desired 1/f-distributed random numbers by multiplying the Cholesky decomposition L by the vector x.
译文如下:
1、对步长为δ的电路进行数值仿真的计算机辅助方法,该电路受1/f噪声影响,其中,电路由具有输入通道(2)、噪声输入通道(4)和输出通道(3)的模型(1)描述,
其中,输入通道(2)和输出通道(3)的行为由微分方程组或代数微分方程组描述,
其中,输出向量(OUTPUT)由输入通道(2)上存在的输入向量(INPUT)和噪声输入通道(4)上存在的噪声向量(NOISE)y的1/f分布随机数计算,以及
其中,噪声向量y通过以下步骤生成:
确定1/f噪声的期望频谱值P,
确定要生成的随机数数量的值n,
确定强度常数const,
形成维度为(n×n)的协方差矩阵C,通过以下公式确定协方差矩阵C的每个元素e(i, j):
e(i, j) = const ⋅ δ β + 1 ⋅ i - j + 1 β + 1 - 2 i - j β + 1 + i - j - 1 β + 1, where i, j = 1, ..., n,其中, i,j = 1, ..., n
形成协方差矩阵C的Cholesky分解L,
对每个要生成的1/f噪声随机数序列执行以下步骤:
形成来自正态分布在(0,1)中的随机数的长度为n的向量x,以及
通过将Cholesky分解L乘以向量x生成所需的1/f分布随机数的长度为n的向量y。
分析:
该申请为2001年提交的关于计算机辅助的方法,在审查过程中,原审查部门以权利要求1所述的仿真方法构成一种心理行为或数学方法为由,认为权利要求1根据EPC第52(2)条被排除在可专利性之外。但是,在后续上诉过程中,委员会认为:仿真受1/f噪声影响的电路构成了一个充分定义的技术目的,可用于功能受限于该目的的计算机实现方法;计算机实现的仿真方法的特定技术应用本身构成了制造过程的重要组成部分,并在实际生产之前主要是作为中间步骤。有鉴于此,不能仅仅因为此类仿真方法尚未包含物理最终产品而否认其具有技术效果。
(参见:https://www.epo.org/law-practice/case-law-appeals/recent/t051227ep1.html)
例5(EP2833303A1):
A method for solving multidimensional optimization problems on a set of feasible solutions {S1, ..., Sn} of a discrete combinatorial problem comprising steps of:
calculating optimization values for the set of feasible solutions {S1, ..., Sn} by using a set of optimization functions {f1, ..., fk} ;
calculating mean values µ(fi) to the set of optimization functions {f1, ..., fk} according to
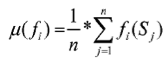
calculating standard deviation values s(f) to the set of optimization functions {f1, ..., fk} according to
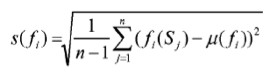
normalize the optimization values for the set of feasible solutions {S1, ..., Sn} according to
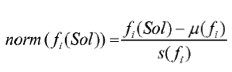
accumulate the normalized optimization values norm (fi(Sol) ) according to
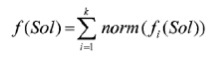
find a minimum for the accumulated normalized optimization values
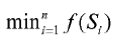
译文如下:
1、在离散组合问题的可行解集合{S1, ..., Sn}上求解多维优化问题的方法1,包括以下步骤:
通过使用优化函数集合{f1, ..., fk}计算可行解集合{S1, ..., Sn}的优化值;
根据(下方公式)计算优化函数集合{f1, ..., fk}的均值;
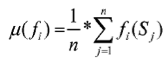
根据(下方公式)计算优化函数集合{f1, ..., fk}的标准偏差值s(f);
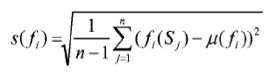
根据(下方公式)标准化可行解集合{S1, ..., Sn}的优化值;
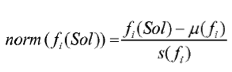
根据(下方公式)累加标准化的优化值norm (fi(Sol));
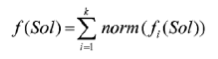
为累加的标准化的优化值找到最小值
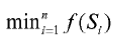
分析:
该申请为2013年提交的优化算法,在审查过程中,审查员指出:计算机实现既未在权利要求1中明确规定,也不能从权利要求1的当前措辞中而承认其是隐含的。在整个申请中,要求保护的方法作为抽象方法呈现,没有任何“计算机实现”的条件,没有定义计算机实现。此外,优化问题的复杂公式不足以暗示该方法必须由计算机实现。委员会认为,如果计算机手段的使用确实是必不可少的,那么就有必要将计算机实施作为一项基本特征纳入方法。此外,优化问题的复杂公式不足以暗示该方法必须由计算机实现。
(参见:https://www.epo.org/law-practice/case-law-appeals/recent/t161820eu1.html)
撰写建议
由上述实例可见,欧洲专利局对涉及人工智能算法的专利,对于适格性问题整体上比较严格。在审查实践中,基于从整体上确定所要求保护的主题是否具有技术性这一原则,需要权利要求的撰写能够体现出其是通过将数学方法应用于某一技术领域和/或(被)适应于特定的技术实施,对服务于技术目的的技术效果做出贡献。例如,权利要求限定的技术特征应该体现出该方法必须由计算机实现,或者服务于一个充分定义的技术目的等。
3.4 日本的人工智能专利实务
本节将介绍在日本专利法下人工智能(AI)相关的专利实务。
3.4.1与AI发明审查相关的重要规范性文件修改时间表
日本专利局(JPO)非常重视与AI相关的专利审查,分别于2018年、2019年和2021年发布了相关的审查标准的变化和案例指引,如下表所示。

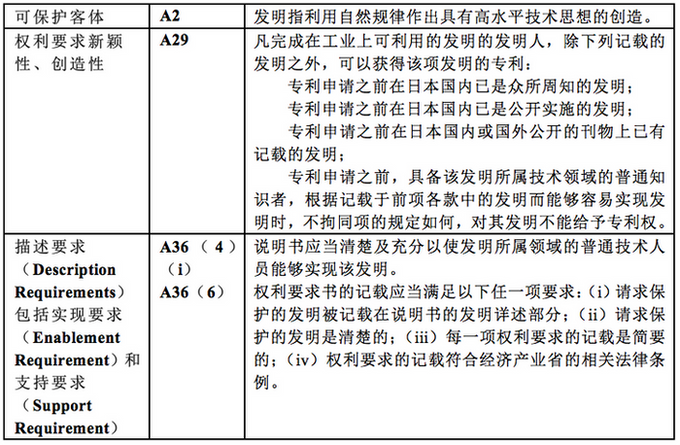
3.4.2 权利获取阶段考虑的《日本特许法》主要条款
3.4.3关于客体适格性
(1)两步法
关于客体适格性,JPO 规定了两步法来判断:
第一步为通用准则,即根据发明是利用自然规律做出具有高水平技术概念的创造;
第二步为针对计算机软件相关的发明的特别准则,这根据基于软件观点的概念来进行。
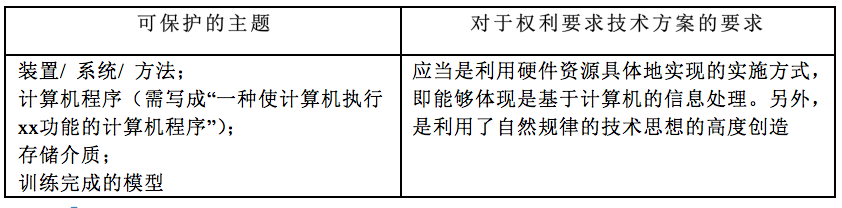
在第一步中,如果发明被认为是数学公式、人类的心理活动、主观安排(例如玩游戏的规则本身)、单纯的信息表达等,则不具客体适格性。对于计算机软件相关的发明,如果具体化地(concretely)执行设备的控制或关于控制的处理,或者基于技术特性例如物体的物理、化学、生物或电特性具体化地执行信息处理,则认为具有客体适格性,而不必再转到第二步根据基于软件观点的概念来进行;如果无法确定是否具备客体适格性,则需要转到第二步进行判断。在第二步中,如果通过软件的信息处理是通过硬件资源来具体化地实现,或者处理器或其操作方法是以软件和硬件资源彼此协作地工作来运行,则认为具有客体适格性。
从以上可以看出,JPO 对于客体适格性的宽容度是相对比较高的,与 AI 相关的程序、数据结构、模型等在满足一定条件下是满足适格性要求的。具体而言,除了中国专利审查实践中目前认可的存储介质的保护主题以外,日本还进一步认可满足一定条件的程序、数据、数据结构、机器学习模型等计算机软件相关发明的保护主题。更详细而言,使用硬件资源具体地实现基于软件的信息处理、与该软件关联工作的信息处理装置、其工作方法及记录该软件的存储介质都能够被认为是利用了自然规律的技术思想的高度创造。其中,对于与人工智能技术相关的程序、数据结构、机器学习模型等与软件相关的保护主题而言,在根据其权利要求的记载能够其明确规定了基于计算机的信息处理的情况下,可以被认为满足客体适格性。然而,如果要保护的数据仅仅是信息的单纯表达,而没有规定如何基于计算机的信息处理,则仍不满足客体适格性。
(2)实例分析
【例1】:
A trained model for causing a computer to function to output quantified values of reputations of accommodations based on text data on reputations of accommodations, wherein;
the model is comprised of a first neural network and a second neural network connected in a way that the said second neural network receives output from the said first neural network;
the said first neural network is comprised of an input layer to intermediate layers of a feature extraction neural network in which the number of neurons of at least one intermediate layer is smaller than the number of neurons of the input layer, the number of neurons of the input layer and the number of the output layer are the same, and weights were trained in a way each value input to the input layer and each corresponding value output from output layer become equal;
weights of the said second neural network were trained without changing the weights of the said first neural network; and
the model causes the computer function to perform a calculation based on the said trained weights in the said first and second neural networks in response to appearance frequency of specific words obtained from the text data on reputations of accommodations input to the input layer of the said first neural network and to output the quantified values of reputations of accommodations from the output layer of the said second neural network.
译文如下:
1.一种基于宿舍的声誉的文本数据促使计算机用于输出合格的宿舍声誉值的训练模型,其特征在于,所述模型包括第一神经网络与第二神经网络,以所述第二神经网络从所述第一神经网络接收输出的方式连接;
所述第一神经网络包括特征提取神经网络的输入层到中间层,其中至少一个中间层的神经元数量小于所述输入层的神经元的数量,所述输入层的神经元的数量与所述输入层的数量相同,训练权重使得输入到输入层的每个值与从输出层输出的每个对应的值变得相等;
不改变所述第一神经网络的权重,训练所述第二神经网络的权重;
响应于从输入到所述第一神经网络的输入层的宿舍声誉的文本数据中获得的特别词的出现频率,基于所述第一与第二神经网络的所述训练权重,所述模型促使计算机用于执行计算,并从所述第二神经网络的输出层输出宿舍声誉的合格值。
分析:
JPO认为,这件申请的主要内容是利用神经网络处理文本信息,通过对文本数据中反映宿舍声誉的特别词汇出现的频率进行分析。权利要求的核心是计算机程序,日本的专利审查指南认为这样的技术方案是可专利的客体,理由是由于通过使用硬件资源具体地实现了软件的信息处理,因此权利要求1的训练模型是利用自然法则的技术思想的创造,因此属于“发明”。
(3)撰写建议
建议多维度地记载用于保护不同主题的实施例,具体而言,除了与中国国内审查实践同样认可的权利要求的主题之外,建议根据人工智能技术的保护要点及其实现形式,在说明书中进一步补入诸如程序、数据结构、机器学习模型等与软件相关的保护主题,以使得申请人能够在日本多维度地获得更为全面的保护范围。
3.4.4关于创造性
(1)创造性审查
根据日本专利审查指南中的规定,判断专利申请是否具有创造性的具体步骤包括:
① 理解要求保护的发明;
② 找出一篇最接近本发明的对比文件;
③ 将本发明与对比文件进行比较,找到相同的技术特征和区别技术特征;
④ 针对区别技术特征进行推理。
其中推理部分具体包括:
①首先考虑该区别技术特征是否是本领域技术人员容易想到的技术创新,比如:从公知材料中选择最合适的材料,数值范围的优化或最优化,等同物的置换,具体应用的技术变更,申请人自己承认的内容等;如果该区别技术特征不是本领域技术人员容易想到的技术创新,则本发明具有创造性;
②如果该区别技术特征属于本领域技术人员容易想到的技术创新,则继续讨论是否有动机,例如对比文件和本申请之间是否具有:A技术领域的相关性,B课题的共通性,C功能、作用的共通性,D引用发明中是否具有启示,或属于公知常识(上述A-D中的任意单独一项,均可以认为具有动机);如果不存在动机,则本发明具有创造性;
③如果存在动机,则继续讨论是否具有否定上述逻辑推理的要素存在,例如:A阻碍要因(不同引用文献之间,在技术上存在障碍而不能结合),B有利的发明效果,C商业上的成功、长期未解决的课题等,其中阻碍要因是答复创造性问题的杀手锏。
根据审查指南,AI 发明的创造性判断适用一般原则,并且不区分技术特征和非技术特征,而是应考虑权利要求记载的全部特征。特别地,根据审查指南提供的示例,AI相关专利申请是否满足创造性的要求(Inventive Step)的主要判断维度包括:
① 是不是仅仅使用AI技术来系统化“人类行为”;
② 是不是仅仅是基于输入数据预测输出结果的改进方法;
③ 用于机器学习的训练数据(training data)的修改,是不是仅仅是已知数据的组合且没有显著的效果;
④ 是不是对用于机器学习的训练数据(training data)的预处理(preprocessing)。
具体而言,
a)对于AI发明,如果单纯地使用AI将由人工操作的任务变成计算机化处理或者将已知的方法系统化,则被认为不具备创造性,换言之,如果仅仅是单纯地使用人工智能技术将由人类进行的处理(例如,由人类手动计算的公式、操作方法)进行系统化而使其由计算机来处理的发明、或者将用于根据原始输入数据来生成预测结果的预测方法单纯地从现有技术变更为人工智能技术,则往往会被认为上述改进是本领域技术人员能够预料的,而创造性不会被认可;
b)如果通过输入数据的选择/变更能够获得有益效果,则被认为具备创造性,反之如果输入数据的选择/变更仅是已知数据的组合未获得有益效果,则不具备创造性,换言之,由于在利用相关关系不明确的数据对训练数据进行变更(例如添加到输入数据中)时,存在产生数据噪声的可能性,所以如果本发明能够通过对训练数据进行变更而产生难以预料的显著技术效果,则会被认可创造性,反之,如果对训练数据的变更只是能够被本领域技术人员预料到相关关系的数据组合、且并未产生显著技术效果,则创造性不会被认可;
c)如果对输入数据的预处理未被公开且能产生有益效果,则被认为具备创造性,反之不具备,换言之,通过对用于作为输入的训练数据实施一定的预处理而变更训练数据的形式以提高目标输出数据的精度会被认为是单纯的设计手段的变更,而创造性不会被认可,但是,如果对训练数据实施的预处理未被现有技术公开且产生了显著技术效果,则创造性能够被认可。
(2)实例分析
【例1】
A cancer level calculation apparatus that calculates a possibility that a subject person has cancer, using a blood sample of the subject person comprising:
a cancer level calculation unit that calculates a possibility that a subject person has cancer, in response to an input of measured values of A marker and B marker that have been obtained through blood analysis of the subject person,
the cancer level calculation unit including a neural network that has been trained through machine learning using training data to calculate an estimated cancer level in
response to the input of the measured values of A marker and B marker.
译文如下:
1.一种使用受试者的血液样本来计算受试者患有癌症的可能性的癌症水平计算装置,包括:
响应于通过受试者的血液分析获得的A标记和B标记的测量值的输入,计算受试者患有癌症的可能性的癌症水平计算单元;
所述癌症水平计算单元包括神经网络,所述神经网络通过使用训练数据的机器学习训练,响应于A标记和B标记的测量值的输入,以计算估计的癌症水平。
分析:
JPO认为这样的权利要求缺乏创造性,理由是:现有技术中存在这样的方案:一种癌症水平计算方法,医生对受试者的血液样本分析来计算受试者患有癌症的可能性,包括使用通过受试者的血液分析获得的A标记和B标记的测量值来计算受试者患有癌症的可能性的步骤。在机器学习领域中,使用训练的神经网络,基于受试者的数据输入计算受试者患有某种疾病的可能性,这些输入的数据可能是人的生物数据,输出数据是患有疾病可能性的数据,这些都是众所周知的,因此该专利缺乏创造性。
这表明,根据JPO审查指南,如果技术特征与人工智能算法相结合的发明,即利用人工智能算法解决技术问题,如果相关的技术手段是已知的,而采用的人工智能算法也是已知,仅仅是已知的算法应用到新场景中,算法和技术手段都未获得改进,这样的专利是缺乏创造性的。
【例2】
A dementia stage estimation apparatus comprising:
a speech information obtainment means for obtaining a speech information on a conversation between a questioner and a respondent;
a speech information analysis means for analyzing the speech information, and then specifying a speech section by the questioner and a speech section by the respondent;
a speech recognition means for converting, through speech recognition, the speech information on the speech section by the questioner and the speech section by the respondent into text and then outputting a character string;
a question topic specification means for specifying a question topic by the questioner based on the result of the speech recognition; and
a dementia stage determination means for inputting, to a trained neural network, the question topic by the questioner and the character string of the speech section by the respondent to the question topic in an associated manner with each other, and then determining a dementia stage of the respondent,
wherein the neural network is trained through machine learning using training data so as to output an estimated dementia stage, in response
to an input of the character string of the speech section by the respondent in an associated manner with the question topic by the questioner.
译文如下:
1.一种痴呆阶段评估装置,包括:
语音信息获取装置,用于获得提问者和答复者之间对话的语音信息;
语音信息分析装置,用于分析语音信息,然后标定提问者的语音部分和答复者的语音部分;
语音识别装置,用于通过语音识别,将提问者的语音部分和响应者的语音部分的语音信息转换成文本,然后输出字符串;
问题主题标定装置,用于根据语音识别的结果通过提问者标定问题主题;及
痴呆阶段确定装置,用于将提问者问题主题于响应者针对所述问题主题的语音部分的字符串以相互关联的方式输入到训练的神经网络,然后确定答复者的痴呆阶段;
其中,所述神经网络使用训练数据通过机器学习进行训练,以便响应于答复者的语音部分的字符串与提问者的问题主题相关联,来输出评估的痴呆阶段。
分析:
现有技术文件涉及一种痴呆阶段评估装置,其包括:语音信息获取装置,用于获得关于提问者和答复者之间的对话的语音信息;语音识别装置,用于通过语音识别将语音信息转换为文本并输出字符串;及痴呆阶段确定装置,用于向训练的神经网络输入已由语音识别装置转换成文本的字符串,然后确定答复者的痴呆阶段,其中,通过机器学习使用训练数据训练神经网络,以便响应于字符串的输入输出评估的痴呆阶段。
JPO认为该专利相对于现有技术具有创造性的原因在于,本领域技术人员通过某种预处理修改训练数据,这种训练数据是用于机器学习的神经网络的输入,以便提高神经网络的估计精度。现有技术中未公开这样的技术特征,用于将提问者问题主题的语音部分的字符串以相互关联的方式输入到训练的神经网络,然后确定答复的痴呆阶段的技术,这也不是一般的技术常识。权利要求1的发明带来了显著的效果,即通过将提问者问题主题和答复者的答复(对应的字符串)以相关联的方式标定,进行高度精确的痴呆阶段评估。
这件申请具备创造性的关键在于训练数据的预处理,将提问者的问题主题与答复者答复的字符串进行关联,这个关联是现有技术未披露的,即使现有技术已经披露了利用神经网络进行痴呆阶段评估的技术方案,该发明依然具有创造性。
综合上述两个示例可以分析得出,人工智能领域的技术方案若要具备创造性,必须在以下两个方面具有改进,一是在技术上或者算法上具有本领域技术人员不容易预测的特征,这可以表现为训练数据的预处理;二是在算法有新的改进。而只是将已知的算法应用到新场景中,相关的场景中采用的技术手段也是已知,取得的技术效果也是可以预测的,相关的发明缺乏创造性
(3)撰写建议
在说明书中对本发明的训练数据进行描述时,尽量确定各相关关系所起到的有益技术效果。进而,针对训练数据的变更所带来的相关关系的变化,进一步明确该变化的相关关系相对于原有的相关关系所产生的显著技术效果。另外,针对优化训练数据的预处理的情况,进一步描述对该预处理的优化所带来的相关关系的变化及其显著技术效果。并且,对于相关关系的变化和预处理的优化所带来的相关关系的变化,可以补充性地描述其相对常规手段变化的突破点。由此,为实质审查时的创造性审查提供足够的争辩基础。
3.4.5 关于公开不充分与说明书支持
(1)描述要求
所谓的“描述要求(Description Requirements)”包括了“实现要求(Enablement Requirement)”和“支持要求(Support Requirement)”两种。“实现要求”类似于中国专利法第26条第3款中关于说明书充分公开的规定,其要求应当在说明书中以本领域技术人员能够实施的程度明确且充分地记载本发明的详细说明。“支持要求”类似于中国专利法第26条第4款中关于以说明书为依据的规定,其要求权利要求所要求保护的发明不能超过说明书中针对本发明的详细说明的记载范围。
JPO 认为,在针对 AI 的相关技术领域,通常使用用于机器学习的包含多种类数据的训练数据,训练数据一般要满足如下两个条件,即基于说明书中的公开内容,可以认识到存在某种关系的条件,例如多种类型的数据之间的相关性,或者根据一般的技术知识,可以推测多种类型数据之间存在关系。也就是说,说明书一般要公开输入数据与输出数据之间的关联性,除非这种数据的关联性是本领域技术人员可以推测的。
因此,判断某个AI相关申请是否满足“实现要求”和“支持要求”关键在于:用于AI机器学习的多种类型数据之间的相关关系(correlation)即关联性是否明确。这里的“是否明确”包括申请人是否在申请文件中以足够多的信息予以描述,或者是否属于本领域技术人员能够轻易明确的。根据 JPO 公开的示例,上述相关关系可以通过如下方式来明确,即可以通过如下方式证明多种类型的数据之间存在相关关系:
① 在说明书中直接地具体记载多种类型的数据之间的相关关系;
②在说明书中通过描述或统计学分析,直接地证明多种类型的数据之间的相关关系;
③在说明书中通过针对已形成的人工智能算法模型进行性能评价,根据该性能评价的结果,间接地证明多种类型的数据之间的相关关系;
④虽然说明书中未记载或证明多种类型的数据之间的相关关系,但本领域技术人员能够根据申请时的技术常识合理推断出相关关系的存在。
另外,需要特别注意的是:
a)针对通过人工智能被预测为具有某种功能的产品的发明,在例如通过人工智能算法模型的预测处理而得到预测结果的情况下,如果该人工智能算法模型的预测处理的精度未被检验,则在日本专利审查实务中通常会认为由于人工智能算法模型的该预测结果并非对实际制造的产品的评价而无法代替对实际制造的产品的评价,从而会认定为说明书的记载不满足“实现要求”;
b) 在为了获得更大的保护范围而在权利要求中以上位概念较宽地概括了训练数据中的个别类型的数据时,如果在说明书中仅仅记载了训练数据中的个别类型的数据之间存在相关关系,而并未记载与以上位概念较宽地概括出的数据有关的相关关系,则会产生概括较宽的数据之间的相关关系得不到说明书支持的情况。
(2) 实例分析
【例1】
A sugar content estimation system comprising:
a storage means for storing face images of people and sugar contents of vegetables produced by the people;
a model generation means for generating a determination model through machine learning, to which a face image of a person is input and from which a sugar content of a vegetable produced by the person is output, using training data containing the face images of the people stored in the storage means and the sugar contents of the vegetables,
a reception means for receiving an input of an face image; and
a processing means for outputting, using the generated determination model that has been generated by the model generation means, a sugar content of a vegetable produced by a person that is estimated based on the face image of the person inputted to the reception means.
译文如下:
一种含糖量估计系统,包括:
存储装置,用于存储人的面部图像和由人生产的蔬菜的含糖量;
模型生成装置,用于使用包含存储在存储装置中的人的面部图像和蔬菜的含糖量的训练数据,通过机器学习生成确定模型,人的面部图像被输入到所述确定模型,并且由所述确定模型输出由人生产的蔬菜的含糖量,
接收装置,用于接收面部图像的输入;以及
处理装置,用于使用由所述模型生成装置生成的确定模型来输出所述由人生产的蔬菜的含糖量,所述含糖量是基于输入到所述接收装置的所述人的面部图像来估计的。
分析:
JPO认为,该专利申请仅指出“人的面部图像”和“由人生产的蔬菜的含糖量”,这两者之间有特定的相关关系,却没有明确的指明或者详述这种相关关系是怎么样的,而本领域技术人员在申请日之时也无法明确这两者之间的联系为何。即,用于AI机器学习的两个类型数据(输入数据和输出数据)之间的相关关系不明确。因此,该专利申请的权利要求1不满足“描述要求”中的“实现要求”。
【例2】
A body weight estimation system comprising:
a model generation means for generating an estimation model that estimates a body weight of a person based on a feature value representing a face shape and a body height of the person, through machine learning using training data containing feature values representing face images as well as actual measured values of body heights and body weights of people;
a reception means for receiving an input of a face image and body height of a person;
a feature value obtainment means for obtaining a feature value representing a face shape of the person through analysis of the face image of the person that has been received by the reception means; and
a processing means for outputting an estimated value of a body weight of the person based on the feature value representing the face shape of the person that has been received by the feature value obtainment means and the body height of the person that has been received by the reception means, using the generated estimation model by the model generation means.
The body weight estimation system as in Claim 1, wherein the feature value representing a face shape is a face-outline angle.
译文如下:
1.一种体重估计系统,包括:
模型生成装置,用于使用训练数据通过机器学习来生成基于表示人的脸部形状和身高的特征值来估计人的体重的估计模型,训练数据包括代表面部图像的特征值以及人体的身高和体重的实际测量值;
接收装置,用于接收人的面部图像和身高的输入;
特征值获得装置,用于通过分析经由接收装置接收到的人的面部图像来获得代表人的面部形状的特征值;以及
处理装置,用于基于表示特征值获取装置已经接收到的人的脸部形状的特征值和特征值获取装置已经接收到的人的身高的特征值,输出人的体重的估计值。接收装置,使用由模型生成装置生成的估计模型。
2.根据权利要求1所述的体重估计系统,其特征在于,表示面部形状的特征值是面部轮廓线角度。
说明书概述:说明书中仅描述并图示了面部轮廓线角度作为“代表人的面部形状的特征值”,没有其他特征值。
分析:
JPO认为,该专利申请仅仅描述了人脸的面部轮廓角度(face-outline angle)与人体体重之间的对应关系,而通过申请文件无法确定其他类型的脸型特征数据与人体体重之间也是有联系的。因此,该专利申请的权利要求1不满足“支持要求”,而权利要求2满足。
(3)撰写建议
为尽量满足“实现要求”,建议分层次地明确训练数据中的多种类型的数据之间的对应关系。具体而言,针对构成训练数据中的各种类型的数据的每一种类型,在清楚地区分上位概括的数据和位于其下位的各项数据的同时,进一步具体地明确各上位概括的数据和其下位数据与其他上位概括的数据和其下位数据之间的对应关系。由此,使得说明书的记载充分,以实现权利要求的由宽至窄的层次性布局。
为尽量满足“支持要求”,建议针对各数据之间的对应关系,明确地描述各对应关系所反映的相关关系。具体而言,针对各对应关系,尽量在说明书中明确地记载该对应关系所反映的一定的相关性、即多种类型的数据之间的相关关系。对于不易于通过文字描述直接体现相关性的对应关系,建议通过对训练数据采用统计学分析而得到的图表数据、针对人工智能算法模型的性能评价结果、以及通过其他试验方式等得到的数据,而直接或间接地证明相关关系的存在及其合理性。此外,尽管在说明书中并非必须明确地记载对于本领域技术人员能够根据申请时的技术常识合理推断出的相关关系,但仍建议以如上所述的方式在说明书中予以明确,以应对因各国技术环境的差异所引起的审查员对于技术常识的认定差别。由此,能够进一步为权利要求中的各项数据之间的相关关系提供说明书支持。
3.5 韩国的人工智能专利实务
3.5.1 与AI发明审查相关的重要规范性文件修改时间表

3.5.2 与专利权的获得相关的主要条款
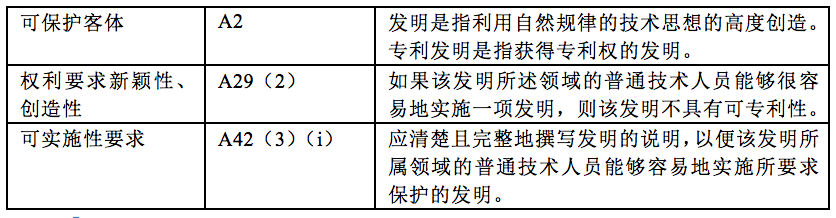
在权利获取阶段考虑的《韩国发明专利法》(《韩国特许法》)和《审查指南》主要条款如下表所示。
3.6.3 客体适格性问题
(1)客体条件
在针对专利保护客体的审查中,韩国相对灵活和宽松。对于AI相关的发明,KIPO审查指南要求人工智能的信息处理过程能够通过硬件具体实现。然而,在韩国的审查实践中并不会对AI相关发明的客体适格性进行严格评定。技术思想更倾向于根据新颖性/创造性而不是适格性来被评定。
AI相关发明的客体条件等同于计算机相关发明的客体条件,具体可通过如下图(来源:发明实用新型专利审查标准(韩国特许厅,2020.8))所示的步骤判断AI相关发明的客体适格性。

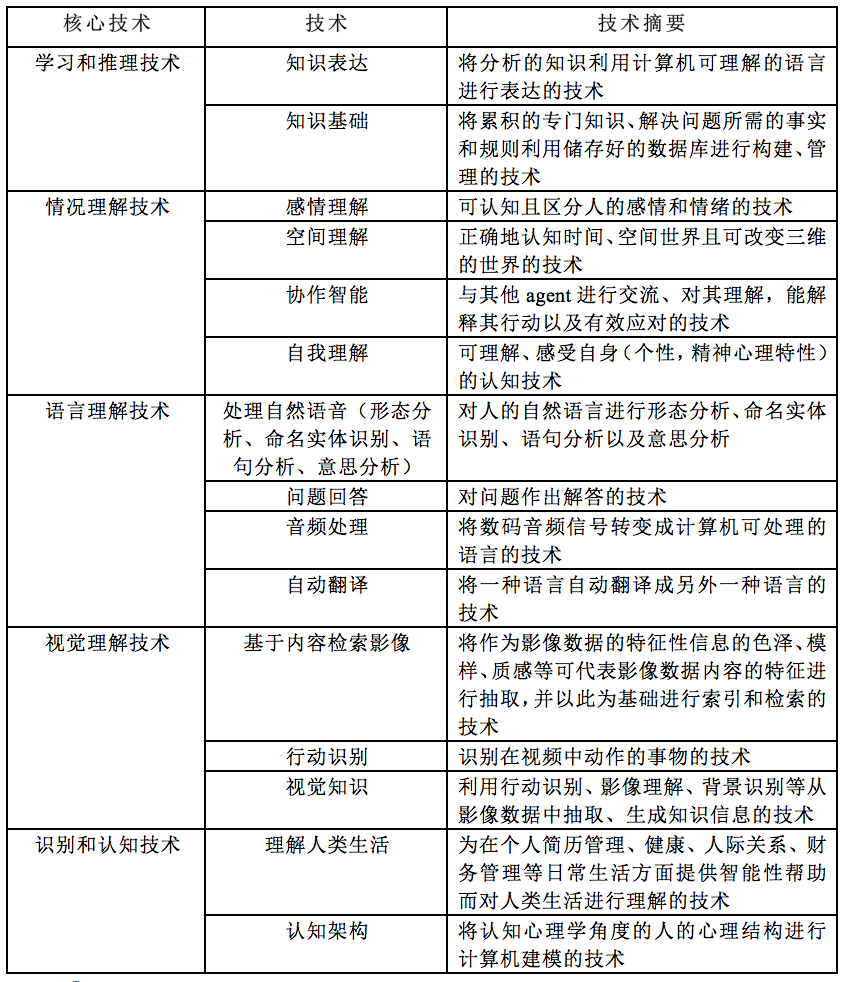
更具体而言,依据韩国未来创造科学部2016年发布的信息通信研发技术分类,对AI技术可作如下所示的分类表【表1-1】。按照该技术分类表,AI技术可能涉及计算机软件程序发明。根据韩国专利审查指南,软件程序发明需要符合如下要求:“软件的信息处理过程通过硬件具体实现的时候,与该软件协同运行的信息处理器、其运行方法以及记录该软件的计算机可读的载体可以认定为利用自然规律的技术思想的创造。另外,软件的信息处理通过硬件具体实现的情况是指通过计算机读取软件,以软件和硬性协同的具体手段,实现对符合使用目的的信息进行运算或加工,从而实现合乎使用目的的特定信息处理装置或该等运行方法。”
因此,若软件的信息处理不能通过硬件具体实现,则该发明不属于利用自然规律的技术思想的创造。有关AI的软件发明能够通过硬件具体实现的时候,该发明就可以被认定为韩国特许法上的发明。软件发明的范畴包括产品、方法、记录软件程序的计算机可读的载体以及在计算机可读的载体上所记录的软件程序。
此外,有关AI的发明有可能会涉及商业方法发明,此时该发明需要满足一般发明所应符合的专利要件和上述有关软件程序所需的条件。
如果有关AI的发明符合软件程序发明或商业方法发明所要求的专利标准,那么该发明也应能够获得专利权,以保护开发新技术的权利人的利益,奖励其贡献,从而促进产业发展。按照类似逻辑,AI作出的外观设计如果满足韩国外观设计保护法所要求的专利要件,那么也应该通过赋予专利权而保护新设计的权利人的利益,并促进产业发展。
【表1-1】
(2)实例分析
韩国大法院2007Hu265判决:“要构成商业方法发明,需要计算机上依软件进行的信息处理能够通过硬件具体实现。另外,判断申请发明是否是利用自然规律的发明,需要依权利要求整体进行判断,因此,即使权利要求所记载的发明中有一部分利用了自然规律,但是如果权利要求整体不被认定为利用了自然规律,则该发明不属于特许法上的发明。”
特许法院2007heo2957判决:“商业方法发明的权利要求不应是利用人的精神活动等的或单纯地利用计算机或互联网的泛用性功能的技术,而应该为软件被计算机读取后,通过与硬件的具体相互协同手段,被用来具体实行为达成特定目的的信息处理的被构建的信息处理装置或该等运行方法。商业方法发明的权利范围需要在上述信息处理装置或该等运行方法被构建的范围内被认定。因此为了主张被诉侵权发明属于已注册的商业方法发明的权利范围内,被诉侵权发明中应包括体现上述商业方法发明的特性的专利发明的构成要素和构成要素之间的有机结合关系。”
分析:
有关AI的发明若涉及商业方法发明,则该发明只有满足一般发明所应符合的专利要件和有关软件程序所需的条件时,才能够进一步满足AI发明客体适格性的要求。
(3)撰写建议
建议撰写权利要求时,在保证权利要求中记载的技术方案满足发明保护客体的一般要求(即属于利用自然规律创造的技术方案)的同时,还要保证权利要求中记载的技术方案满足人工智能的信息处理过程能够通过硬件具体实现的特别要求。此外,建议多维度地记载用于保护不同主题的实施例以使得申请人能够在韩国多维度地获得更为全面的保护范围。
3.6.4 创造性问题
(1)创造性审查
根据韩国审查指南的相关规定,创造性的一般性审查标准为:根据申请前的对比文件和公知常识,判断本领域技术人员是否能够容易地获得本申请所涉及的发明。对于AI相关发明的创造性审查,可参考计算机相关专利申请的判断方法:考虑相关技术在不同领域应用的技术难度、解决的是否为计算机领域常见的技术问题以及获得的是否为计算机领域常见的技术效果。
同时,KIPO认为,一项仅仅描述人工智能技术用途的权利要求不太可能获得专利,除非有用于解决技术问题的区别性技术配置(例如,训练数据、数据预处理、经过训练的模型、损失函数等)。否则,所主张的发明将仅被视为一种已知的人工智能技术,而这种技术可以很容易地由该发明所述领域的普通技术人员完成。上述观点同样适用于那些仅使用人工智能技术将可能已经实施或以前为人工实施的过程系统化或计算机化,只是简单地修改了常规的人工智能技术的设计(例如,对训练模型的简单更改)以及仅在常规人工智能技术基础上添加或替换已知技术的发明。
(2)实例分析
权利要求:
一种利用根据判断股价上升/下降的AI算法而显示不同颜色的AI图表的股份信息提供方法,…包括根据用于辨别股价走势的算法来显示不同颜色的步骤,…
分析:
判断股价上升/下降的标准和据此显示不同颜色的方法为股票投资或图表分析领域中广泛应用的惯用技术手段,未限定特有的信息处理的情况下将本领域惯用技术手段单纯实现为AI算法是不具有创造性的发明(参考特许法院2013HEO1788判决)。
(3)撰写建议
关于创造性要求,KIPO建议具体说明区别化的技术配置(例如,训练数据、数据预处理、经过训练的模型、损失函数等),并详细说明由技术配置直接产生的、超出常规人工智能技术效果的技术效果,也就是说,需避免仅就技术效果做出结论性陈述(例如提高处理速度、有效处理海量数据、减少错误或提供准确的预测等)。有关创造性要求的一些撰写技巧如下:
1、人工智能训练数据发明
提供有关如何为获得训练数据处理原始数据的详细信息,例如,描述如何从输入数据中提取特征,如何生成训练数据(例如通过标准化、规范化或矢量化方式)。
解释可以从数据预处理中得出的特定效果或改进(例如,通过对与“运动跟踪”功能有关的闭路电视视频图像实施数据预处理时,由于考虑了对象的运动,因此能够更准确地识别视频图像中的对象,而现有技术仅使用视频图像来识别对象)。
2、人工智能建模发明
描述建模的特定配置,例如训练环境的配置、模型评估、多模型链接、并行或分散式处理以及超参数的优化。
提供由特定配置引起的关于训练速度、训练模型的预测准确性等的效果,这些效果必须是常规人工智能技术无法实现的。
3、人工智能应用发明
描述经过训练的模型的输出数据的特定用途以及以特定方式使用输出数据的效果,例如,通过使用经过训练的模型(如在车祸中被破坏的汽车部件上的标签)的输出数据来计算每种维修类型的估算费用,这样用户就可以根据自己选择的维修类型方便地预测其保险费的增长。
此外,建议从多个角度(训练数据、训练模型、应用服务等)撰写权利要求以有利于侵权判定。具体而言,针对训练数据,对原始数据进行预处理时,可以将训练数据的生成方法、装置、程序存储介质作为权利要求限定特征,如果“以数据结构限定由计算机执行的处理内容”,也可以将数据存储介质作为权利要求限定特征;针对训练模型本身,训练模型的内部结构包含技术特征的情形,可以将限定训练模型结构的方法、装置、程序存储介质作为权利要求限定特征;针对应用服务,将方法、装置、程序存储介质作为权利要求限定特征。
3.6.5 关于公开充分
(1)可实施要求
根据《韩国专利法》第42条第3款第i项,应清楚且完整地撰写发明的说明,以便该发明所属领域的普通技术人员能够容易地实施所要求保护的发明。关于人工智能发明,KIPO建议对包括技术问题、解决方案和具体技术配置(例如,训练数据、数据预处理,经过训练的模型和损失函数等)进行说明,以使该发明所属领域的普通技术人员能够实施所主张的发明,除非技术配置是所属领域众所周知的。
对此,说明书中应该具体记载本领域普通技术人员实现AI相关发明的手段:a)例如,训练数据、数据预处理方法、训练模型等;b)例如,训练模型的输入数据和输出数据之间的相关关系;c)可简单说明公知的训练模型(模型名称、基本结构、来源等)。
(2)实例分析
权利要求1:
一种房屋的温度自动控制系统,包括:
存储部,用于存储过去的每日气象数据及房屋温度历史数据;
训练模型生成部,用于生成及其训练模型,所述机器训练模型使用所述每日气象数据中的温度、…、雾霾浓度数据中的至少一项和所述房屋温度控制历史数据作为训练数据;
收集部,用于收集来自气象局服务器的气象信息;及
输出部,其利用所述机器训练模型,将通过所述当前气象信息预测出来的房屋温度自动控制信息输出出去。
说明书:
未具体记载雾霾浓度数据和房屋温度自动控制信息之间的相互关系,而且未给出可证明上述相互关系的实施例。
判断:
由于普通技术人员无法实施在权利要求中记载的发明,其不满足公开充分/支持条件。
(3)撰写建议
韩国专利审查指南针对不同类型的人工智能发明提供了一些撰写技巧,具体如下(为了简化说明,以下内容将人工智能模型训练发明进一步分为两类——“人工智能训练数据发明”是用于数据预处理的发明,“人工智能建模发明”是旨在构建机器学习模型的发明):
1、人工智能训练数据发明
描述如何处理原始数据以生成、更改、添加或删除训练数据,以及原始数据和训练数据之间的相关性(即说明为什么使用原始数据以及为什么要以某种方式对训练数据进行预处理)。
2、人工智能建模发明
指定任何技术配置或方法以实施或训练模型(例如,如果使用神经网络集合来训练模型,则应确认所使用的神经网络以及使用该神经网络训练模型的过程或手段)。
3、人工智能应用发明
提供有关训练模型的输入数据和输出数据之间的相关性的详细信息,即:(1)指定训练数据;(2)描述用于解决技术问题的训练数据的特征之间的相关性;(3)使用训练数据或训练方法表示要训练的机器学习模型;(4)描述通过使用训练数据和方法解决技术问题的训练模型如何生成。