



点击章节题目阅读其他章节:
第二章 主要国家和地区的人工智能产业政策、知识产权的立体保护和专利申请态势

第四章 人工智能的著作权保护
4.1.1 概述
与人工智能相关的著作权保护的客体,即作品,可能包含以下几种:
产品设计图等图形作品和模型作品
人工智能的产品设计图和模型作品,可以作为产品设计图等图形作品和模型作品的兜底保护。但是产品设计图的著作权保护只能保护从平面到平面的复制,即阻止他人复制我们的图纸本身,而不能阻止他人按照图纸设计出同样的产品。
计算机软件
在对人工智能软件的“创作思想”申请专利权的保护的同时,也可以对软件的“表达形式”进行著作权的登记。涉及人工智能技术的软件种类繁多,数量巨大,而且软件的功能各异,几乎涵盖了人工智能的各技术分层(基础支撑层、通用技术层和应用层)。
美术作品
人工智能也会涉及到各种美术作品,包括软件的logo图形、人工智能的虚拟机器人形象设计等。
每一款人工智能的虚拟形象都花费了设计师的巨大心血,一款别具匠心的设计也就存在着较大被仿冒的可能,保护好人工智能的虚拟形象也是一个比较棘手的问题。涉及到形象保护的,首先考虑的就是著作权法的相关规定。人工智能的虚拟形象可以划归美术作品的范畴,人工智能企业作为美术作品的设计者(或者委托设计者)对其形象享有版权,擅自使用他人的人工智能的形象的行为即属于侵犯著作权。
人工智能的人机交互界面,如果具有较强的独创性和艺术设计,也可以作为美术作品获得著作权保护。
下面主要介绍人工智能的计算机软件保护。
4.1.2 人工智能软件的著作权保护期限
根据中国《计算机软件保护条例》第十四条,软件著作权自软件开发完成之日起产生。
自然人的软件著作权,保护期为自然人终生及其死亡后50年,截止于自然人死亡后第50年的12月31日;软件是合作开发的,截止于最后死亡的自然人死亡后第50年的12月31日。
法人或者其他组织的软件著作权,保护期为50年,截止于软件首次发表后第50年的12月31日,但软件自开发完成之日起50年内未发表的,本条例不再保护。
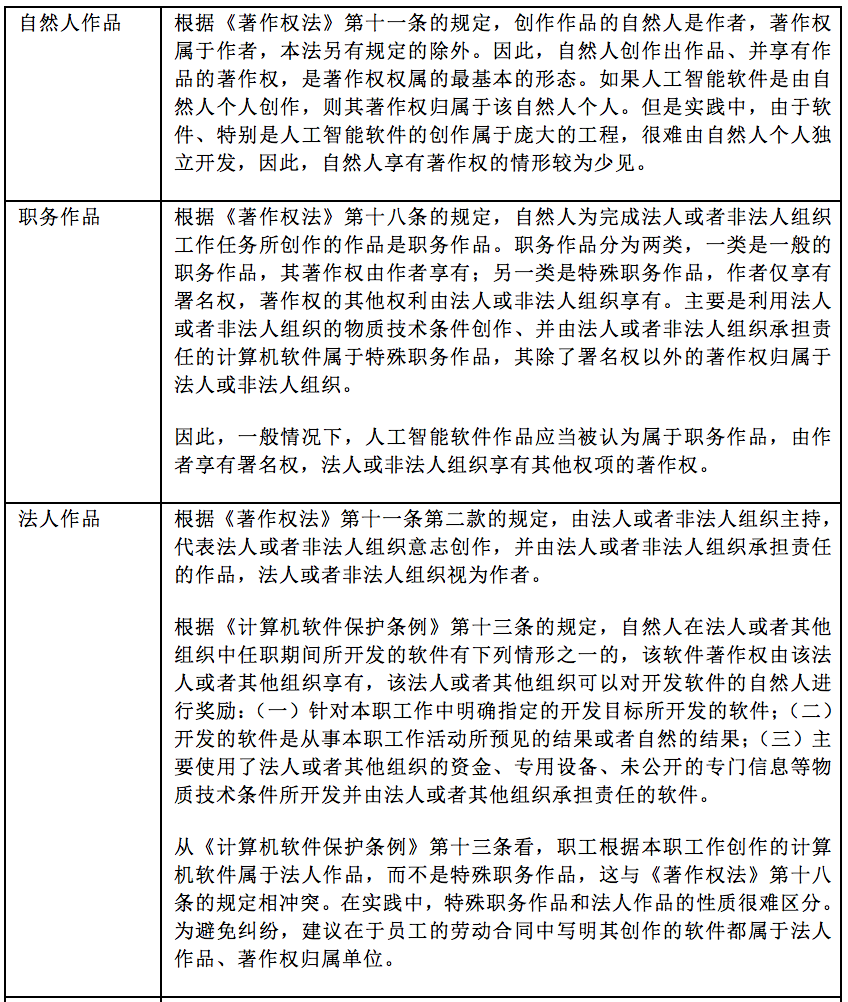
4.1.3 人工智能软件的著作权权属
根据中国《著作权法》的规定,人工智能软件的著作权权属可以分为以下几类。

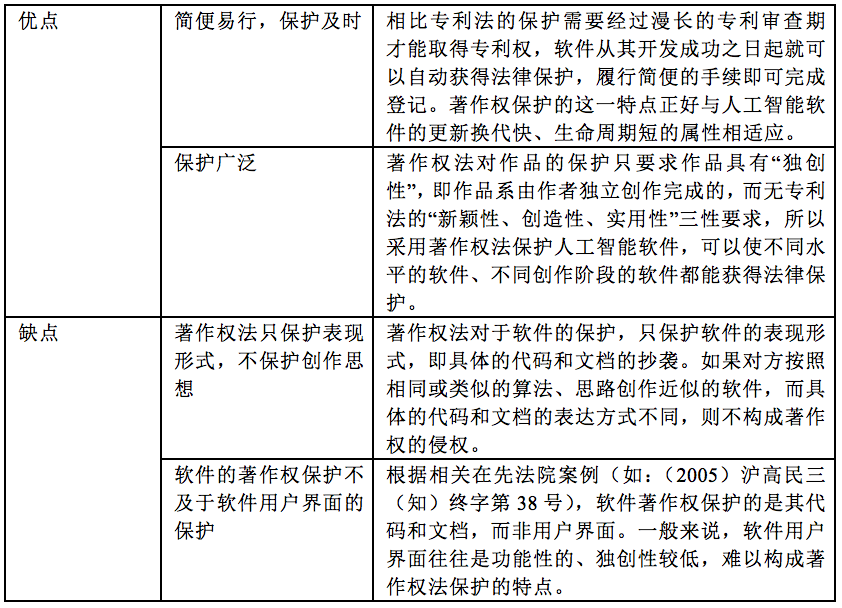
4.1.4 人工智能软件的保护特点
4.1.5 人工智能软件的保护对象
计算机软件是指“计算机程序及其有关文档”。
计算机程序,包括“代码化指令序列”,或者“可以被自动转换成代码化指令序列的符号化指令序列或者符号化语句序列”。同一计算机程序的源代码和目标代码为同一作品。
文档,指“用来描述程序的内容、组成、设计、功能规格、开发情况、测试结果及使用方法的文字资料和图表等”,例如,程序设计说明书、流程图、用户手册等。(《计算机软件保护条例》的第二条、第三条第一款和第二款)
一般来说,从软件的功能模块、函数、源程序、目标程序到程序说明书、流程图、用户手册等均可以成为著作权法的保护对象。
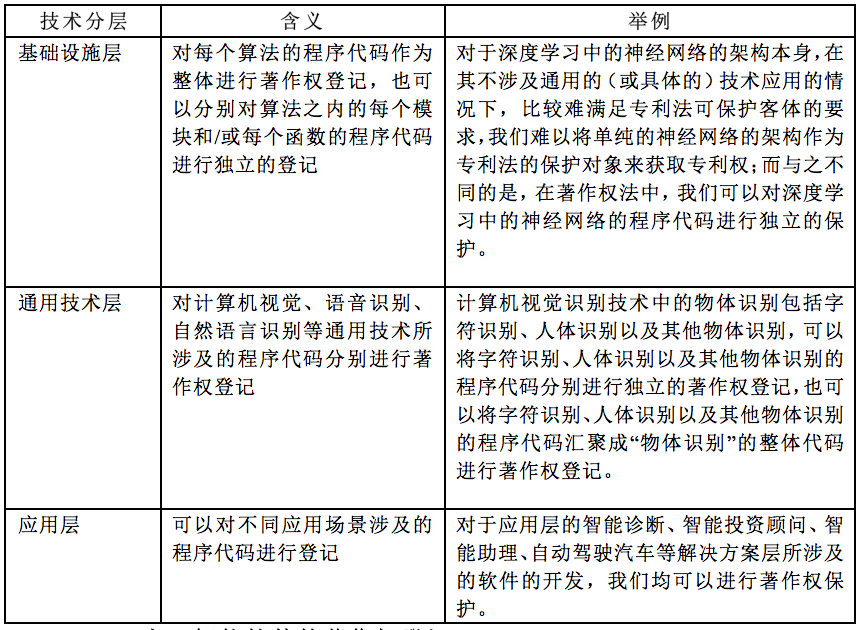
具体而言,针对人工智能的各技术分层,其软件著作权保护中的文档部分大同小异,下面简述分析其计算机程序的保护客体:
4.1.6 人工智能软件的著作权登记
根据中国《著作权法》,著作权自作品创作完成时自动享有,不以著作权登记为前提。但是进行著作权登记有利于证明权属、避免未来的权属纠纷,并且便利将来的诉讼维权。因此,还是建议对人工智能软件进行著作权登记。
4.2 人工智能的生成物的著作权保护
对于基础支撑层和通用技术层的人工智能,可能不涉及产出物的著作权保护。而对于应用层的人工智能,诸如自动写作机器人、自动作曲机器人、自动绘画机器人,则涉及到这些人工智能创作出来的生成物(文字作品、音乐、美术作品等)是否受著作权保护的问题。
4.2.1 传统观点:人工智能的生成物不属于著作权法保护的作品
按照传统的著作权法理论和实践,对于这种人工智能创作出来的内容不被认为是著作权法意义上的作品,不能得到著作权保护。其理由为:
1. 并非自然人创作。根据著作权法,作品必须是由自然人创作出来,虽然法人或非法人组织也可以被认定为作者,但这种认定属于法律拟制,而且法人作品从根本上也是源于自然人的创作。
2. 没有独创性。认为人工智能创作出来的作品仅仅只是对数据的加工、编排,不符合创作的定义,不认为具有独创性。
当2015年猴子“自拍照”在美国引起版权归属争议时,美国版权局就明确指出,只有人类的作品才受到美国版权法的保障,该局不会接受由自然、动物或植物创作的作品来登记版权,因此,猴子的自拍照并无版权。旧金山法院也最终判决支持版权局的决定:动物不能拥有照片版权。
4.2.2 实践的发展:有限度的承认获得著作权保护
虽然存在上述法律上的障碍,但是由于实践中人工智能创作的作品大量存在,并且事实上也具有重要的经济价值和法律保护的意义,因此,学术界和实务界也开始越来越多的倾向于对人工智能创作的作品进行著作权保护。
主张对人工智能生成物进行著作权保护的理由为:
1. 人工智能仅仅只是工具,并非创作者,人工智能生成物的实际创作者本质还是人而非人工智能。
2. 具有著作权法所要求的独创性。人工智能生成物并非是简单的、机械的数据处理,更是体现了人类的智慧和创造。随着人工智能技术的发展,人工智能生成物已经能达到人类创作作品的水准,在不提前说明的情况,一般人很难从外观区分出哪些是人工智能生成物,哪些是自然人创作的作品。
典型案例:
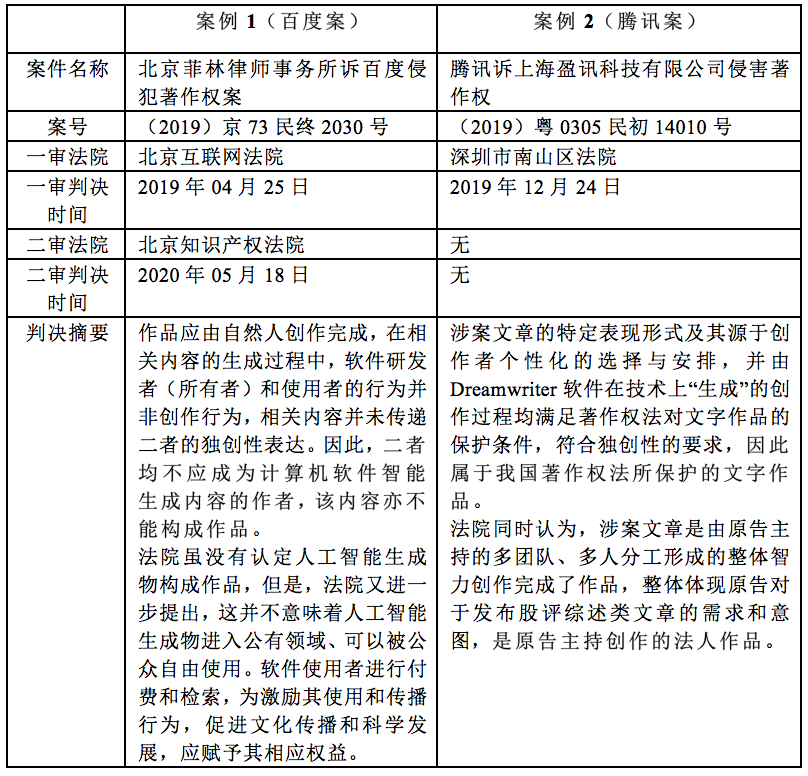
这两案判决的分歧:
· 在案例1中,百度案持保守立场,认为人工智能软件的生成物不属于著作权法的作品,但是认定应当对于软件的使用者赋予相应的权益;
· 在案例2中,腾讯案则更进一步,认为人工智能软件仅仅只是工具,使用人工智能软件创作出来的生成物本质还是人类的创作成果,从而应认定依据著作权法予以保护。
人工智能可以分为三个层次:弱人工智能、强人工智能、超强人工智能。对于弱人工智能,仅仅相当于强化版的工具,使用其创作来的作品可以当然的算作自然人创作的作品,受著作权法保护;对于超强人工智能,目前尚未完全实现。对于强人工智能,从目前的实践看,还是倾向于对其进行著作权法的保护(如腾讯案),或者在不承认其构成作品的前提下,给予一定程度上的保护(如百度案)。
但是不论百度案还是腾讯案,均只是对个别情况作出的判断,难以说是对于人工智能生成物的著作权给予了明确的、普遍意义的指引。特别是对一些复杂的情况,可能以后还有赖于更多的判决。我们将继续关注相关的司法及立法动态,为人工智能企业提供更深入的分析和指导。
4.2.3 人工智能生成物的著作权权属
从腾讯案的司法判决来看,中国法院目前倾向于对人工智能生成物进行保护,但保护的前提是认定其生成物仍然属于人类创作的成果,作者是人类而非人工智能本身。在解决了能否受著作权法保护的问题后,有必要分析人工智能生成物的著作权权属应归属哪一方主体。
· 人工智能的研发者
有观点认为,人工智能的生成物从根本上说应归属于人工智能软件的研发者。因为在人工智能生成的过程中,软件的研发者对此付出的投入和技术成果是最多的,人工智能软件的使用者仅仅只是输入了数据或指令就得到生成物,其中的创作过程都是由人工智能软件完成。因此,人工智能生成物的著作权应当归属于人工智能的研发者,以更好的保护研发者的利益、鼓励和刺激人工智能行业的发展。
· 人工智能的使用者
另一种观点认为,人工智能软件本质只是工具,人类利用人工智能软件创作出的作品,就像利用其他创作的工具创作出作品一样,其著作权应当归属于人工智能软件的使用者。例如,人类利用相机拍摄出照片,虽然相机厂商为相机的设计、研发付出了巨大的贡献,而拍照的过程只是简单的按一下快门,但照片的著作权权属仍然应归于拍照的人。此外,另一个理由是,研发者已经通过出售人工智能软件获得了足够的商业利润,不应再将其保护范围延及至人工智能的生成物,否则将使人工智能软件的使用者丧失对其产出的作品的控制,也不利于人工智能软件产业的成长。
· 法院的观点——人工智能的使用者
在百度案中,法院虽不赞成人工智能的生成物属于著作权法意义上的作品,但是又进一步指出应对人工智能的使用者赋予相关权益:“对于软件研发者(所有者)来说,其利益可通过收取软件使用费用等方式获得,其开发投入已经得到相应回报;且分析报告系软件使用者根据不同的使用需求、检索设置而产生的,软件研发者(所有者)对其缺乏传播动力。因此,如果将分析报告的相关权益赋予软件研发者(所有者)享有,软件研发者(所有者)并不会积极应用,不利于文化传播和科学事业的发展。对于软件使用者而言,其通过付费使用进行了投入,基于自身需求设置关键词并生成了分析报告,其具有进一步使用、传播分析报告的动力和预期。因此,应当激励软件使用者的使用和传播行为,将分析报告的相关权益赋予其享有,否则软件的使用者将逐渐减少,使用者也不愿进一步传播分析报告,最终不利于文化传播和价值发挥。”
在腾讯案中,法院认为:涉案文章是由原告主持的多团队、多人分工形成的整体智力创作完成了作品,整体体现原告对于发布股评综述类文章的需求和意图。涉案文章在由原告运营的腾讯网证券频道上发布,文章末尾注明“本文由腾讯机器人Dreamwriter自动撰写",其中的“腾讯"署名的指向结合其发布平台应理解为原告,说明涉案文章由原告对外承担责任。故在无相反证据的情况下,本院认定涉案文章是原告主持创作的法人作品。
从这两案判决来看,腾讯案认定人工智能软件Dreamwriter的使用者原告腾讯公司系该涉案文章的作者,仅将人工智能软件作为创作的工具。法院认为涉案文章体现了原告公司主创人员的特殊的选择和安排,表达了软件使用者的独特个性,体现了软件使用者的意志。而百度案中,虽然不承认对人工智能生成物应予以著作权保护,但是强调对其应当赋予一定权益的保护,而该权益的主体应当属于人工智能软件的使用者,而非研发者。
总结:
根据中国著作权法关于“作品必须是由自然人创作”的规定,认定人工智能软件的使用者系人工智能生成物的作者,可能是比较合乎法理常情的推论,否则难以合理的解释“创作”这一过程体现在何处、如何是“人类”的创作行为。
· 标明人工智能软件生成物的义务
尽管肯定了人工智能的使用者对其生成物享有权益,百度案中,法官强调了对于人工智能生成物,使用者应当标注系由某人工智能软件生成。其目的,一是为了向公众说明其作品创作的情况,满足公众的知情权;二是保障人工智能研发者的利益,使相关公众知晓该人工智能软件,扩大人工智能的知名度和影响,从而实现人工智能的使用者和研发者的利益的平衡。
· 生成物著作权权属的约定
在腾讯案中,人工智能软件Dreamwriter的研发者腾讯科技(北京)有限公司与软件的使用者原告深圳市腾讯计算机系统有限公司约定了该软件的生成物的著作权权属归原告所有。法院并未对这一权属约定予以评判。
考虑到目前立法对于人工智能生成物的著作权并未有明确规定,建议人工智能企业在软件许可协议中,就人工智能生成物的著作权权属予以明确约定,以避免未来可能发生的纠纷。
4.3 机器学习涉及到的著作权问题
机器学习是人工智能的关键技术,在人工智能技术快速发展并广泛应用的当今,机器学习技术不仅带来诸多社会问题,也对现有法律制度带来挑战。机器学习以大量的“资料(Data)”作为训练数据,这些资料可以分为两种:不受著作权法保护的数据、信息或作品,以及受著作权法保护的作品。关于前一类,受到个人信息保护法等数据法规的保护;而对于后一类,受著作权法保护的作品,则可能遇到各种著作权侵权的风险。
机器学习分为三个阶段,分别是输入阶段、学习阶段和输出阶段。输入阶段主要是将收集到的数据输入到初步模型,以便初步模型可通过算法分析数据;学习阶段依赖于计算机强大的处理能力与运算能力对训练数据进行分析,优化模型并完成任务;输出阶段是机器学习的最后一个阶段,通过模型对任务进行处理,得到相应的答案。在每一个阶段,可能遇到的著作权问题各异。
4.3.1 输入阶段
机器学习中输入训练数据的来源大致可以分为这几种方式:
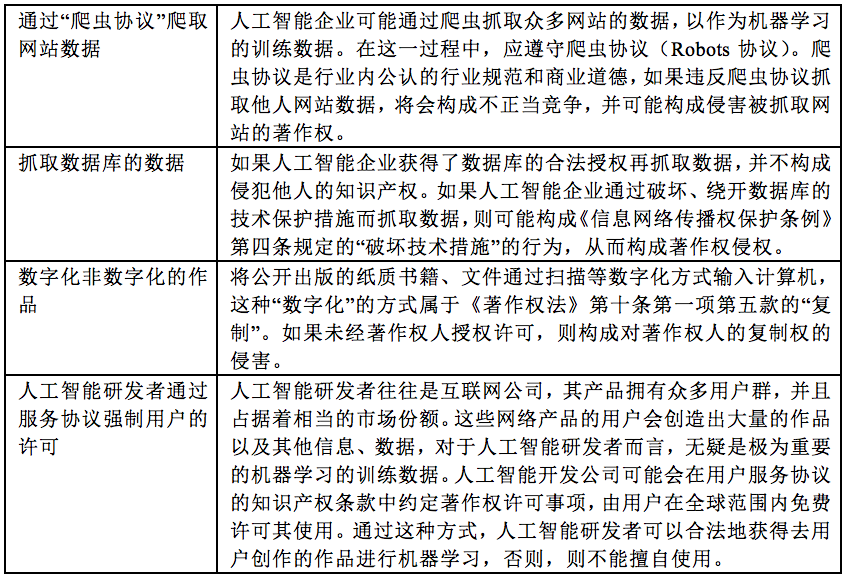
总结:
在未经授权的情况下,抓取、复制他人作品以输入,存在较大的侵犯著作权风险。但是,输入阶段往往是发生在公司内部的行为,一般难以被发现,因此实践中被提起著作权侵权的可能性较低。
4.3.2 学习阶段
学习阶段的过程涉及到对训练数据的复制、翻译、改编、汇编等行为。这些使用行为,是否构成对作品的著作权侵权?有以下几种观点。
· 构成著作权侵权
有观点认为,机器学习在学习阶段使用作为训练数据的著作权作品,属于使用复制、翻译、改编、汇编等行为使用了作品,因此,机器学习使用这些作品并须获得著作权人的授权许可,否则将构成著作权侵权。
但是,这种观点并未考虑到机器学习的现状和特殊性。由于机器学习需要使用海量的数据才能完善,如果严苛保护,要求人工智能企业事先分别从每件作品的作者取得授权,几乎是不可能完成的任务,也将极大的损害人工智能行业的正常发展,并不利于人工智能行业和著作权人之间的利益平衡。
· 属于合理使用
国外现有的立法和司法实践似乎倾向于将机器学习适用于合理使用制度,以豁免其侵权责任。如欧盟2019年《单一数字市场版权指令》中的文本数据挖掘例外(第3、4、7条),美国法院认定文本数据挖掘构成合理使用而驳回作家协会(Authors Guild)针对谷歌图书项目的一系列侵权之诉。
与此相应,国内外的大多数学者也主张采用合理使用制度解决机器学习作品的著作权问题。
中国《著作权法》第二十四条规定了合理使用制度,而满足合理使用需符合四项要件:(1)特定的十三项情况;(2)指明作者姓名或者名称、作品名称;(3)不得影响该作品的正常使用;(4)不得不合理地损害著作权人的合法权益。
对于机器学习中使用他人的作品,只是将他人作品作为训练数据输入计算机系统、供机器进行练习,其过程发生在机器层面,因此一般情况下不会影响作品的正常使用,也没有不合理地损害著作权人的合法权益。
但是适用合理使用条款的困难之处在于,要求必须符合该条规定的十三项特定情形,而这十三项特定情形中并没有明确包含机器学习。十三项情况中,最接近的可能是“(六)为学校课堂教学或者科学研究,翻译、改编、汇编、播放或者少量复制已经发表的作品,供教学或者科研人员使用,但不得出版发行”,但该项强调的是“科学研究、供科研人员使用”,机器学习的过程虽然是与科技研究有关,但毕竟是商业活动,而该项的要求是非商业、纯研究领域,适用该项有一定的难度。此外,十三项情况的兜底项“(十三)法律、行政法规规定的其他情形”,虽然看似开放性条款,但由于明确规定了“法律、行政法规规定的”,而目前并无法律、行政法规对机器学习认定为合理使用的情况,因此也不能适用。
因此,在中国目前的《著作权法》的条件下,将机器学习的学习阶段认定为合理使用,存在一定的难度。
· 属于非著作权意义上的使用
还有一种观点认为,在学习过程中对于享有著作权的作品的“使用”,与传统的《著作权法》意义上的“使用”不同。《著作权法》所规定的“使用”,其使用的主体是人,即“人类阅读”;而机器学习时,使用的主体是“机器”,即“机器阅读”。从这个意义上讲,机器学习的过程中使用的作品,只是以机器的方式转换成机器理解的语言进行学习,文本的处理过程只是机械处理的过程,而并非对于作品的使用。因此,机器学习的学习过程应当视为非著作权法意义上的使用,自然也不构成著作权侵权。
总结:
关于机器学习的学习阶段,目前从立法上并没有明确的规定,司法实践中也并没有相关案例参考。学术界主要的观点是认为其构成合理使用或者非著作权法意义上的使用,从而为其免除著作权侵权的风险。未来可能会在立法或司法实践中进一步明确对其性质的认定。
4.3.3 输出阶段
机器学习的学习阶段可能以合理使用或非著作权法意义上的使用来免除侵权风险,但其输出阶段,仍存在较大的著作权侵权风险的可能。
按照机器学习的输出结果是否具有独创性,可将机器学习分为表达型机器学习(Expressive Machine Learning)和非表达型机器学习(Non-Expressive Machine Learning)。非表达型机器学习的输出结果不具有独创性,而表达型机器学习的输出结果是具有一定独创性的。
· 非表达型机器学习:
没有表达性内容输出,机器学习过程中的作品复制没有后续作品表达性内容公众化传播的结果。因此,该类机器学习所创作的作品不会构成与其所学习的作品相同或实质性相似,不负著作权侵权责任。
· 表达型机器学习:
表达型机器学习可以分为普通的表达型和特殊的表达型。普通的表达型是不以特定作者的风格为模型对象;而特殊的表达型,旨在模仿某作者的某种风格。
(1)普通的表达型,其训练数据来源于数量众多作者,其输出的结果融会贯通了多个作者的风格和表达,难以明确与某个特定的作者的作品构成近似,一般来说,不会构成著作权侵权。但是如果虽然来源于多个作者,而输出结果中部分表达明显与某些作者相似,就相似的部分构成著作权侵权。
(2)特殊的表达型,由于其旨在模仿和重现特定作者的作品的表达,以无限接近该作者的创作风格为技术目标的。因此这种人工智能从作品中提取的信息从本质上是某作家一以贯之的个性化表达,并且该种人工智能创作的作品的个性化表达还可能会产生替代学习作者的市场效果。因此,这种情况下,构成著作权侵权的可能性较高。对于这种类型的机器学习,人工智能企业应当事先取得作者的授权许可。
典型案例:
在热播剧《锦绣未央》侵犯著作权一案中,作者秦简被控涉嫌使用“写作软件”抄袭219部作品,历经两年多的维权,12位作家诉《锦绣未央》抄袭案全部胜诉。2019年5月,北京市朝阳区法院作出判决认定:小说《锦绣未央》与温瑞安等12位知名作者在先发表的16部作品相比,就语句而言,或者均使用了独特的比喻或形容,或者均采用了相同或类似的细节描写来刻画人物或事物,或者均采用大量常用语言的相似组合;就情节而言,小说《锦绣未央》采用了上述16部权利作品中具有独创性的背景设置、出场安排、矛盾冲突和具体的情节设计,共存在763处语句、21处情节相同或实质性近似,共计114千字。作者秦简使用的写作软件,通过机器学习他人的作品,并根据使用者的要求输出结果,但是大量采用了其学习内容的语言表达或相似组合,与被学习的多个作品分别构成实质性近似。因此,构成著作权侵权。
机器学习的输出物构成侵权还涉及到侵权主体的确定。如前一节所述,目前的司法实践倾向于将软件使用者认定为人工智能生成物的作者,则侵权责任应由软件使用者承担。但是软件使用者可以《产品质量法》的“瑕疵担保义务”为由,要求人工智能软件的研发者承担赔偿责任。